Multi-layer perceptron
A multi-layer perceptron (MLP) can be used both for classification and for regression. The basic idea of an MLP is the linking of the smallest units – so-called neurons – in a network. Each neuron takes up information from previous neurons or directly via model inputs and processes it. A directional flow of information takes place through this network from inputs to outputs.
A neuron processes its inputs x as a weighted sum plus an ordinate value and transforms the intermediate result with an activation function.
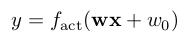
Neurons are usually arranged in layers, which are then linked one after the other. If a network has more than one layer between inputs and outputs, then it is referred to as a multi-layer perceptron.
The structure is illustrated in the figure below.
- Input layer: Has no neurons of its own. Serves as an input layer and defines the number and data type of the inputs.
- Hidden layer: Layer with its own neurons. The layer is characterized by the number of neurons as well as the selected activation function. Any number of hidden layers can be layered one after the other.
- Output layer: Layer with its own neurons. The number of neurons and their activation function are oriented to the application to be implemented.

Supported properties
ONNX support
The following ONNX operators are supported:
- MatMul (matrix multiplication) followed by ADD (add)
- GEMM (general matrix multiplication)
In addition, the following activation functions are supported:
Activation function | Description |
|---|---|
tanh | Hyperbolic tangent (-1.1) |
sigmoid | Sigmoid function – an exponential function (0.1) |
softmax | Softmax – a normalized exponential function – often used for classification (0.1) |
sine | Sine function (-1.1) |
cosine | Cosine function (-1.1) |
relu | "Rectifier" – positive portion is linear – good learning properties in case of deep networks (0, inf) |
abs | Absolute value of the input (0, inf) |
linear/id | Linear identity – simple linear function f(x) = x (-inf, inf) |
exp | A simple exponential function e^(x) (0, inf) |
logsoftmax | Logarithm of softmax – sometimes more efficient than softmax in the calculation (-inf, inf) |
sign | Sign function (-1.1) |
softplus | Sometimes better than relu due to the differentiability (0, inf) |
softsign | Conditionally better convergence behavior than tanh (-1.1) |
Samples of the ONNX support for MLPs from Pytorch, Keras and Scikit-learn can be found here: ONNX export of an MLP.
Supported data types
A distinction must be made between "supported datatype" and "preferred datatype". The preferred datatype corresponds to the precision of the execution engine.
The preferred datatype is floating point 32 (E_MLLDT_FP32-REAL).
When using a supported datatype, an efficient type conversion automatically takes place in the library. Slight losses of performance can occur due to the type conversion.
A list of the supported datatypes can be found in ETcMllDataType.
Further comments
There are no limits on the software side with regard to the number of layers or the number of neurons. With regard to the calculation duration and memory requirement, the limits of the employed hardware are to be observed.