Performance, latencies and configuration
Latency times and their measurability
As described under Execute AI model, the total execution time or total latency of an AI model on the TwinCAT Machine Learning Server consists of different time components.
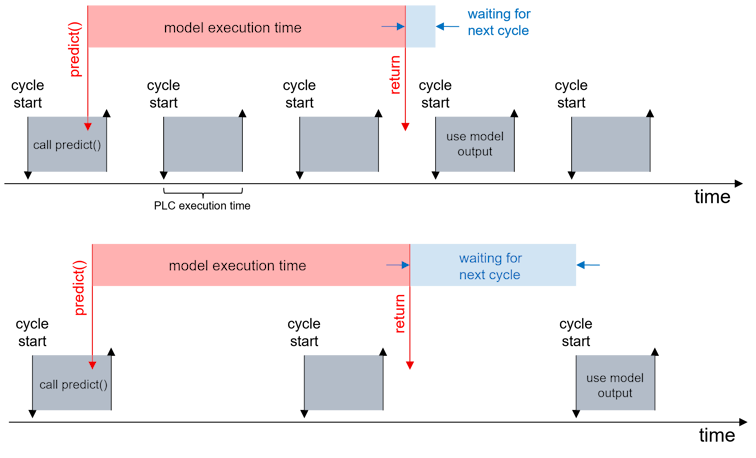
The "model execution timespan" shown in the figure above can be divided into three parts:
- ADS communication between PLC and server
- Server overhead (receiving data, processing and forwarding to the execution unit)
- Model inference time
In addition, there is the time delay caused by the cyclic code execution of the PLC, which is indicated in the figure above as "waiting for next cycle".
The FB_MlSvrPrediction has a structure stLatencyMonitor of type ST_LatencyMonitor as output. This includes the elements:
nInferenceLatency: Describes the pure model inference runtime.nServerLatency: Describes the server overhead.nCommunicationLatency: ADS communication + "waiting for next cycle"
The data is determined in milliseconds and is measured and updated with each inference.
Configuration options and latency effects
Reduction of the model inference runtime
You can reduce this proportion by providing more computing resources for the TcMlServer. If the Execution Provider is set to CPU, the TcMlServer uses the CPU computing resources available in user mode for inference. Please note that cores isolated from TwinCAT are not available to the user mode and that shared cores with TwinCAT are only partially available to the user mode. The TcMlServer also shares resources with other user mode applications, such as the TwinCAT HMI Server, the TwinCAT Scope Server and others. Please also observe the instructions when using CPUs with hybrid architecture.
If you have the option of running the calculation on a GPU, you can set it to Tesla Compute Cluster (TCC) mode (for Windows operating systems). NVIDIA® TCC mode is an operation mode for NVIDIA® GPUs that disables the graphics output and optimizes the GPU exclusively for computing tasks. This means that the GPU is only available for dedicated computing operations. The TcMlServer can then execute inferences on the GPU without competing processes. Details on the TCC mode can be found here: System configuration for GPU operation.
Reduction of server overhead
The part of server overhead is usually negligible. The other parts should rather be minimized. The server uses the CPU computing capacity of the user mode for the necessary actions.
Reduction of ADS communication latency
To minimize ADS communication latency, it is recommended to install the client and the server on the same IPC. This means that ADS communication is handled locally on the device using the main memory. Latency increases considerably with remote ADS communication via the network.
An important factor is the communicated data size. In the case of image processing models, the image size in particular must be considered as an input to the model. The Resize operation can be a decisive factor here. You can execute this in the PLC before the Predict call or insert it as an ONNX operator in the ONNX. The Resize operator, executed on the GPU with the TwinCAT Machine Learning Server, is executed faster than on the CPU with the TwinCAT Vision function, but the difference in ADS communication can be significant.
Reduce the waiting time until the next cycle
You can only shorten this latency by reducing the task cycle time. A short cycle time means that you check at short intervals whether the result is available from the server. This may compete with other states of the PLC program that require longer runtimes. It may be useful to run the Predict call in another, faster task.
Configuration of the TcMlServer on CPUs with hybrid architecture
On hybrid architectures with both performance and efficiency cores, the TcMlServer only works on one core type to minimize latency jitter. By default, the TcMlServer only works on performance cores that are available to the user mode of the IPC.
The preferred core type can be changed in the server configuration file. This can be found under C:\ProgramData\Beckhoff\TwinCAT\Functions\TF38xx-Machine-Learning\TcMlServer\config\server\server.json. The behavior of the TcMlServer can be changed by manipulating the entry e_core_preference_in_hybrid_architecture.
Only use P cores (default): "e_core_preference_in_hybrid_architecture": false
Only use E cores: "e_core_preference_in_hybrid_architecture": true
Changes to the server configuration only take effect after a server restart.
If none of the configured core types are available, the TcMlServer falls back to the available ones and acknowledges the fact with a warning in the log file.