Execute AI model
The execution of an AI model with the FB_MlSvrPrediction is triggered via the Predict method (or PredictBatched in the case of a batched call), which is asynchronous to the PLC task cycle.
The input data type and the output data type (see PlcOpenXml in the Machine Learning Model Manager section), as well as a timeout and a priority are passed to the method.
Send inference order:
When the method is called, the input data area is sent to the server via ADS. The copying process required for this is carried out synchronously in the task cycle. Please note that larger amounts of data require more time. When transferring large amounts of data, such as large image data, the PLC task cycle time must be configured to prevent cycle timeouts.
Edit inference order:
The inference order is then accepted by the TwinCAT Machine Learning Server. If there are multiple requests that cannot be processed at the same time, a queue is created, with higher priorities moving up in the queue. CPU-based inference orders are always processed sequentially, i.e. the queue is particularly relevant here. GPU-based inferences, on the other hand, can be processed in parallel. Each FB instance can only ever have one outstanding request on the server, i.e. the maximum number of requests on the server is the number of active clients.
Request inference result:
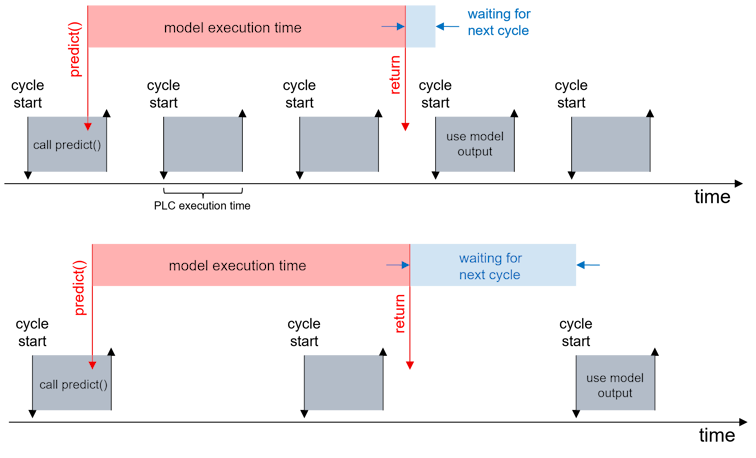
It is important to note that the processing of the asynchronous request can only be monitored with the temporal granularity of the PLC task cycle time. It is therefore important that applications with a low delay budget have the lowest possible cycle times and correspondingly high sampling rates in order to minimize delays caused by time resolution. This is particularly important when interacting with other, computationally intensive and synchronously executed algorithms, e.g. when pre- or post-processing data.
Sample Predict()
Declaration
stModelInput : ST_LemonModelInput; // DUT from PlcOpenXml produced with TC ML Model Manager
stModelOutput : ST_LemonModelOutput; // DUT from PlcOpenXml produced with TC ML Model Manager
fbMlSvr : FB_MlSvrPrediction();
Code:
// Submission of an inference request at the TcMlServer
// and subsequent postprocessing of the inference result
// Submission of the asynchronous inference request to the TcMlServer
IF fbMlSvr.Predict(
pDataIn := ADR(stModelInput),
nDataInSize := SIZEOF(ST_LemonModelInput),
pDataOut := ADR(stModelOutput),
nDataOutSize := SIZEOF(ST_LemonModelOutput),
nTimeout := 100,
nPriority := 0) THEN
IF fbMlSvr.nErrorCode <> 0 THEN
// If nErrorCode -1 is encountered, increase nTimeout
eState := E_State.eError;
ELSE
// Postprocessing of the inference results
END_IF
END_IF
Sample PredictBatched()
Declaration
stModelInputBatch : ARRAY[0..3] OF ST_LemonModelInput;
stModelOutputBatch : ARRAY[0..3] OF ST_LemonModelOutput;
Code
IF fbMlSvr.PredictBatched(
pDataIn := ADR(stModelInputBatch),
nDataInSize := SIZEOF(ST_LemonModelInput),
nBatchSize := 4,
pDataOut := ADR(stModelOutputBatch),
nDataOutSize := SIZEOF(ST_LemonModelOutput),
nTimeout := 100,
nPriority := 0) THEN
In the sample calls, the timeout for the inference request is set to 100 cycles in each case. In the figure above, the result is available after 3 cycles (top) or 2 cycles (bottom). The jitter that may be experienced can be queried via fbMlSvr.nMaxInferenceDuration. This shows the maximum number of PLC cycles that were required to execute an inference. Based on this value, the timeout value can usually be interpreted well.