Performance, Latenzen und Konfiguration
Latenzzeiten und deren Messbarkeit
Wie unter KI-Modell ausführen beschrieben, besteht die Gesamtausführungszeit bzw. Gesamtlatenz eines KI-Modells auf dem TwinCAT Machine Learning Server aus unterschiedlichen zeitlichen Anteilen.
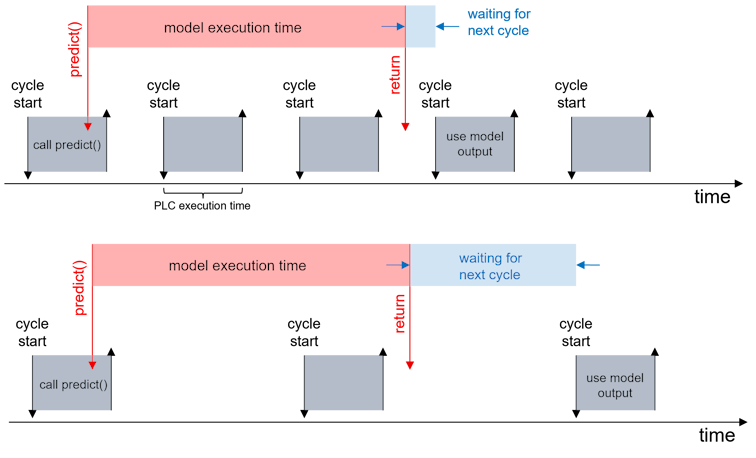
Die Zeitspanne „model execution time“ aus obiger Abbildung ist zu unterteilen in drei Anteile:
- ADS-Kommunikation zwischen SPS und Server
- Server Overhead (Empfang der Daten, Aufbereitung und Weiterleitung an die Ausführungseinheit)
- Modell-Inferenzzeit
Hinzu kommt die zeitliche auflösungsbedingte Verzögerung durch die zyklische Code-Ausführung der SPS, welche in obiger Abbildung mit „waiting for next cycle“ angegeben ist.
Der FB_MlSvrPrediction hat als Output eine Struktur stLatencyMonitor vom Typ ST_LatencyMonitor. Diese beinhaltet die Elemente:
nInferenceLatency: Beschreibt die reine Modell-Inferenzlaufzeit.nServerLatency: Beschreibt den Server Overhead.nCommunicationLatency: ADS-Kommunikation + „waiting for next cycle”
Die Angaben werden in Millisekunden ermittelt und mit jeder Inferenz gemessen und aktualisiert.
Konfigurationsmöglichkeiten und Latenzauswirkungen
Verringerung der Modell-Inferenzlaufzeit
Diesen Anteil können Sie durch Bereitstellung von mehr Rechenressourcen für den TcMlServer verringern. Ist der Execution Provider auf CPU eingestellt, nutzt der TcMlServer die im User-Mode verfügbaren CPU-Rechenressourcen zur Inferenz. Berücksichtigen Sie, dass von TwinCAT isolierte Kerne dem User Mode nicht zur Verfügung stehen und dass shared cores mit TwinCAT nur teilweise dem User Mode zur Verfügung stehen. Ebenso teilt sich der TcMlServer die Ressourcen mit anderen User Mode Anwendungen, wie z. B. dem TwinCAT HMI-Server, dem TwinCAT Scope-Server und weiteren. Beachten Sie darüber hinaus die Hinweise bei Verwendung von CPUs mit Hybridarchitektur.
Sollten Sie die Möglichkeit haben, die Berechnung auf einer GPU auszuführen, können Sie diese (bei Windows Betriebssystemen) in den Modus Tesla Compute Cluster (TCC) versetzen. Der NVIDIA® TCC-Modus ist ein Betriebsmodus für NVIDIA®-GPUs, der die Grafikausgabe deaktiviert und die GPU ausschließlich für Rechenaufgaben optimiert. Damit steht die GPU nur für dedizierte Rechenoperationen zur Verfügung. Der TcMlServer kann dann ohne konkurrierende Prozesse Inferenzen auf der GPU ausführen. Details zum TCC-Modus finden Sie hier: Systemkonfiguration für GPU-Betrieb.
Verringerung des Server Overhead
Der Anteil des Server-Overhead ist in der Regel vernachlässigbar klein. Es sollten eher die anderen Anteile minimiert werden. Der Server nutzt für die notwendigen Aktionen die CPU-Rechenkapazitäten des User Modes.
Verringerung der ADS-Kommunikationslatenz
Um eine möglichst geringe ADS-Kommunikationslatenz zu erhalten, wird empfohlen, den Client und den Server auf demselben IPC zu installieren. Damit wird die ADS-Kommunikation lokal auf dem Gerät über den Arbeitsspeicher abgewickelt. Bei Remote-ADS-Kommunikation über das Netzwerk vergrößert sich die Latenz erheblich.
Ein wichtiger Faktor ist die kommunizierte Datengröße. Bei Bildverarbeitungsmodellen ist dort insbesondere die Bildgröße als Input in das Modell zu betrachten. Ein entscheidender Faktor kann hier die Resize-Operation sein. Diese können Sie in der SPS vor dem Predict-Aufruf ausführen oder als ONNX-Operator in der ONNX einfügen. Der Resize-Operator, ausgeführt auf der GPU mit dem TwinCAT Machine Learning Server, ist zwar schneller ausgeführt als auf der CPU mit der TwinCAT Vision-Funktion, allerdings kann der Unterschied in der ADS-Kommunikation groß ausfallen.
Verringerung der Wartezeit bis zum nächsten Zyklus
Nur durch Verringerung der Task-Zykluszeit können Sie diese Latenzzeit verkürzen. Eine kleine Zykluszeit führt dazu, dass Sie in kurzen Abständen prüfen, ob das Ergebnis vom Server zur Verfügung steht. Dies konkurriert eventuell mit anderen States des SPS-Programms, welche längere Laufzeiten benötigen. Es kann zielführend sein, den Predict-Aufruf in einer anderen, schnelleren Task, auszuführen.
Konfiguration des TcMlServer auf CPUs mit Hybridarchitektur
Auf Hybridarchitekturen mit Performance- und Efficiency-Cores arbeitet der TcMlServer nur auf einem Core-Typ, um den Latenzjitter zu minimieren. Standardmäßig arbeitet der TcMlServer nur auf Performance-Cores, die dem User-Mode des IPC zur Verfügung stehen.
Die Art des präferierten Core-Typ kann in der Server-Konfigurationsdatei verändert werden. Diese ist unter C:\ProgramData\Beckhoff\TwinCAT\Functions\TF38xx-Machine-Learning\TcMlServer\config\server\server.json zu finden. Das Verhalten des TcMlServers kann durch Manipulation des Eintrags e_core_preference_in_hybrid_architecture geändert werden.
Nutze nur P-Cores (Default): "e_core_preference_in_hybrid_architecture": false
Nutze nur E-Cores: "e_core_preference_in_hybrid_architecture": true
Änderungen an der Server-Konfiguration werden nur nach einem Server-Neustart wirksam.
Sofern keine der konfigurierten Core-Typen verfügbar sind, fällt der TcMlServer auf die verfügbaren zurück und quittiert den Umstand mit einer Warnung im Logfile.