KI-Modell ausführen
Die Ausführung eines KI-Modells mit dem FB_MlSvrPrediction wird über die zum SPS-Task-Zyklus asynchrone Methode Predict (oder im Fall eines batched Aufrufs PredictBatched) getriggert.
Der Methode werden der Eingangsdatentyp und der Ausgangsdatentyp (siehe PlcOpenXml im Bereich Machine Learning Model Manager), sowie ein Timeout und eine Priorität übergeben.
Inferenzauftrag absenden:
Beim Aufruf der Methode wird der Eingangsdatenbereich per ADS an den Server gesendet. Der dafür notwenige Kopiervorgang wird synchron im Task-Zyklus ausgeführt. Beachten Sie hier, dass größere Datenmengen mehr Zeit benötigen. Im Falle der Übertragung großer Datenmengen, z. B. großer Bilddaten, muss die SPS-Task-Zykluszeit so konfiguriert werden, dass keine Zykluszeitüberschreitungen auftreten.
Inferenzauftrag bearbeiten:
Der Inferenzauftrag wird dann vom TwinCAT Machine Learning Server entgegengenommen. Bei mehreren Anfragen, die nicht gleichzeitig bearbeitet werden können, wird eine Queue erstellt, wobei höhere Prioritäten weiter vorne in der Queue einsortiert werden. Aufträge von CPU-basierten Inferenzen wird immer sequenziell abgearbeitet, d. h. die Queue ist hier besonders relevant. GPU-basierte Inferenzen lassen sich hingegen parallel abarbeiten. Jede FB-Instanz kann immer nur eine ausstehende Anfrage am Server haben, d. h. die maximale Anzahl von Anfragen am Server ist die Anzahl der aktiven Clients.
Inferenzergebnis abfragen:
Es ist wichtig zu berücksichtigen, dass die Abwicklung der asynchronen Anfrage nur mit der zeitlichen Granularität der SPS-Task-Zykluszeit überwacht werden kann. Es ist daher wichtig, dass Applikationen mit geringem Verzugsbudget möglichst niedrige Zykluszeiten und entsprechend hohe Abtastraten aufweisen, um zeitliche auflösungsbedingte Verzögerungen zu minimieren. Dieser Umstand ist insbesondere im Zusammenspiel mit anderen, rechenintensiven und synchron ausgeführten Algorithmen, z. B. bei der Vor- oder Nachverarbeitung der Daten, von hoher Bedeutung.
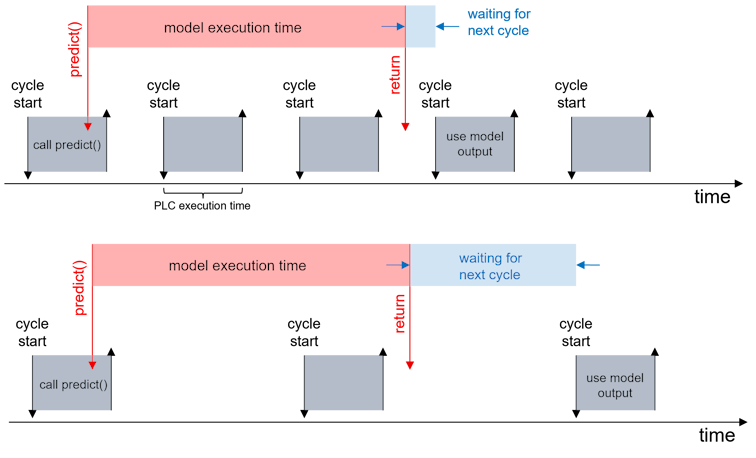
Beispiel Predict()
Deklaration
stModelInput : ST_LemonModelInput; // DUT from PlcOpenXml produced with TC ML Model Manager
stModelOutput : ST_LemonModelOutput; // DUT from PlcOpenXml produced with TC ML Model Manager
fbMlSvr : FB_MlSvrPrediction();
Code:
// Submission of an inference request at the TcMlServer
// and subsequent postprocessing of the inference result
// Submission of the asynchronous inference request to the TcMlServer
IF fbMlSvr.Predict(
pDataIn := ADR(stModelInput),
nDataInSize := SIZEOF(ST_LemonModelInput),
pDataOut := ADR(stModelOutput),
nDataOutSize := SIZEOF(ST_LemonModelOutput),
nTimeout := 100,
nPriority := 0) THEN
IF fbMlSvr.nErrorCode <> 0 THEN
// If nErrorCode -1 is encountered, increase nTimeout
eState := E_State.eError;
ELSE
// Postprocessing of the inference results
END_IF
END_IF
Beispiel PredictBatched()
Deklaration
stModelInputBatch : ARRAY[0..3] OF ST_LemonModelInput;
stModelOutputBatch : ARRAY[0..3] OF ST_LemonModelOutput;
Code
IF fbMlSvr.PredictBatched(
pDataIn := ADR(stModelInputBatch),
nDataInSize := SIZEOF(ST_LemonModelInput),
nBatchSize := 4,
pDataOut := ADR(stModelOutputBatch),
nDataOutSize := SIZEOF(ST_LemonModelOutput),
nTimeout := 100,
nPriority := 0) THEN
In den Beispielaufrufen wird der Timeout für die Inferenzanfrage jeweils auf 100 Zyklen gesetzt. In der obigen Abbildung steht das Ergebnis nach 3 Zyklen (oben) bzw. 2 Zyklen (unten) zur Verfügung. Der unter Umständen erfahrbare Jitter kann über fbMlSvr.nMaxInferenceDuration abgefragt werden. Dieser zeigt das Maximum der Anzahl von SPS-Zyklen, die für die Ausführung einer Inferenz erforderlich waren, an. Anhand dieses Werts lässt sich der Timeout-Wert in der Regel gut auslegen.