FB_ALY_DenStream
DenStream ist eine Implementierung des gleichnamigen unüberwachten, dichtebasierten Clustering-Algorithmus [1]. Er basiert auf dem bekannten Clustering-Algorithmus DBSCAN [2, 3] und eignet sich insbesondere für Datenströme, deren Strukturen sich im Zeitverlauf verändern.
Die Anzahl der Eingangskanäle (im Folgenden als n bezeichnet) für diesen Algorithmus kann vom Benutzer gewählt werden. Diese Eingänge bilden den n-dimensionalen Merkmalsraum, in dem Cluster zu finden sind. In jedem Analysezyklus liefert der Datenstrom dem Algorithmus einen neuen Merkmalsvektor, der als Datenpunkt in diesem Merkmalsraum interpretiert werden kann. Cluster sind separierbare Bereiche mit einer hohen Dichte von Datenpunkten im Merkmalsraum.
In der ersten Phase des Algorithmus werden die eingehenden Datenpunkte sogenannten Mikro-Clustern (MCs) zugeordnet. Diese Mikro-Cluster haben Eigenschaften (wie Mittelpunkt, Gewicht und Varianz), die von den enthaltenen Datenpunkten abhängen. Nur Mikro-Cluster, deren Gewicht eine bestimmte Schwelle überschreitet, gelangen in die zweite Phase und werden vom DBSCAN-Algorithmus geclustert. Somit ist es nicht erforderlich, die Informationen über jeden einzelnen Datenpunkt zu behalten. Dadurch reduziert sich der Speicherbedarf, da es mit der Zeit viel weniger Mikro-Cluster als Datenpunkte gibt. Und auch der Rechenaufwand für den DBSCAN-Algorithmus ist viel geringer, da er über den reduzierten Satz von Mikro-Clustern und nicht über alle Datenpunkte läuft. Außerdem ist es möglich, auf die Gewichte der Mikro-Cluster eine Fading-Funktion anzuwenden. Auf diese Weise verlieren alte Datenpunkte mit der Zeit ihre Bedeutung für den Clustering-Prozess. Dadurch können Änderungen (wie die Verschiebung von Clustern oder ihr Verschwinden/Erscheinen mit der Zeit) vom Algorithmus erfasst werden.
Der DenStream-Algorithmus hat weitere Vorteile gegenüber anderen Clustering-Algorithmen. Der Benutzer muss die Anzahl der Mikro-Cluster nicht im Voraus kennen, da der DenStream-Algorithmus diese Anzahl automatisch bestimmt. Zudem ist der Algorithmus in der Lage, Ausreißer in den Daten zu erkennen, die zu keinem Cluster gehören. Da es sich um einen dichtebasierten Algorithmus handelt, ist es sogar möglich, separate Cluster beliebiger Form zu erkennen (auch wenn sie ineinander verschlungen sind).
Parametereinstellung
Hier geben wir eine kurze Einführung in die Funktionsweise des Algorithmus, hauptsächlich um dem Leser einen schnellen Einstieg in die Parametereinstellung zu ermöglichen. Für ein tiefgreifendes Verständnis des Algorithmus und seiner Parameter weisen wir den Leser auf die genannten Veröffentlichungen hin. Die meisten der hier verwendeten Begriffe und Parameternamen stammen direkt aus diesen Veröffentlichungen.
Die Parameter des DenStream-Algorithmus beeinflussen vor allem folgende Eigenschaften des Algorithmus:
- Die Grobheit der Mikro-Cluster,
- Die maximale Entfernung zwischen Datenpunkten/Mikro-Clustern, damit sie demselben Cluster zugeordnet werden,
- Die Mindestdichte, damit Datenpunkte als Cluster und nicht als Ausreißer erkannt werden,
- Die Fading-Rate, mit der ältere Datenpunkte ihre Bedeutung verlieren.
Die Parameter Epsilon, Lambda und Mu x Beta gehören zur ersten Phase des Algorithmus, der Bildung von Mikro-Clustern.
Nach Möglichkeit wird ein Datenpunkt in das Mikro-Cluster eingefügt, dessen Mittelpunkt dem Datenpunkt am nächsten liegt. Dazu werden die euklidischen Abstände zwischen dem Datenpunkt und den Mittelpunkten aller Mikro-Cluster verglichen und das Mikro-Cluster mit dem geringsten Abstand ausgewählt. Der Datenpunkt kann nur in das Mikro-Cluster eingefügt werden, wenn der Radius des Mikro-Clusters nach dem Einfügen nicht die Schwelle Epsilon überschreitet. Der Radius ist analog zur Varianz aller Datenpunkte, die im Mikro-Cluster enthalten sind. D.h. es können auch Datenpunkte in ein Mikro-Cluster integriert werden, deren euklidische Distanz zum Mittelpunkt des Clusters größer ist als Epsilon, solange genügend andere Punkte im Mikro-Cluster einen geringeren Abstand haben.
Wenn der Datenpunkt nicht in das nächste Mikro-Cluster eingefügt werden kann, wird mit diesem Datenpunkt ein neues Mikro-Cluster erstellt. Das Gewicht des jeweiligen Mikro-Clusters wird mit dem Einfügen eines Datenpunktes um eins erhöht.
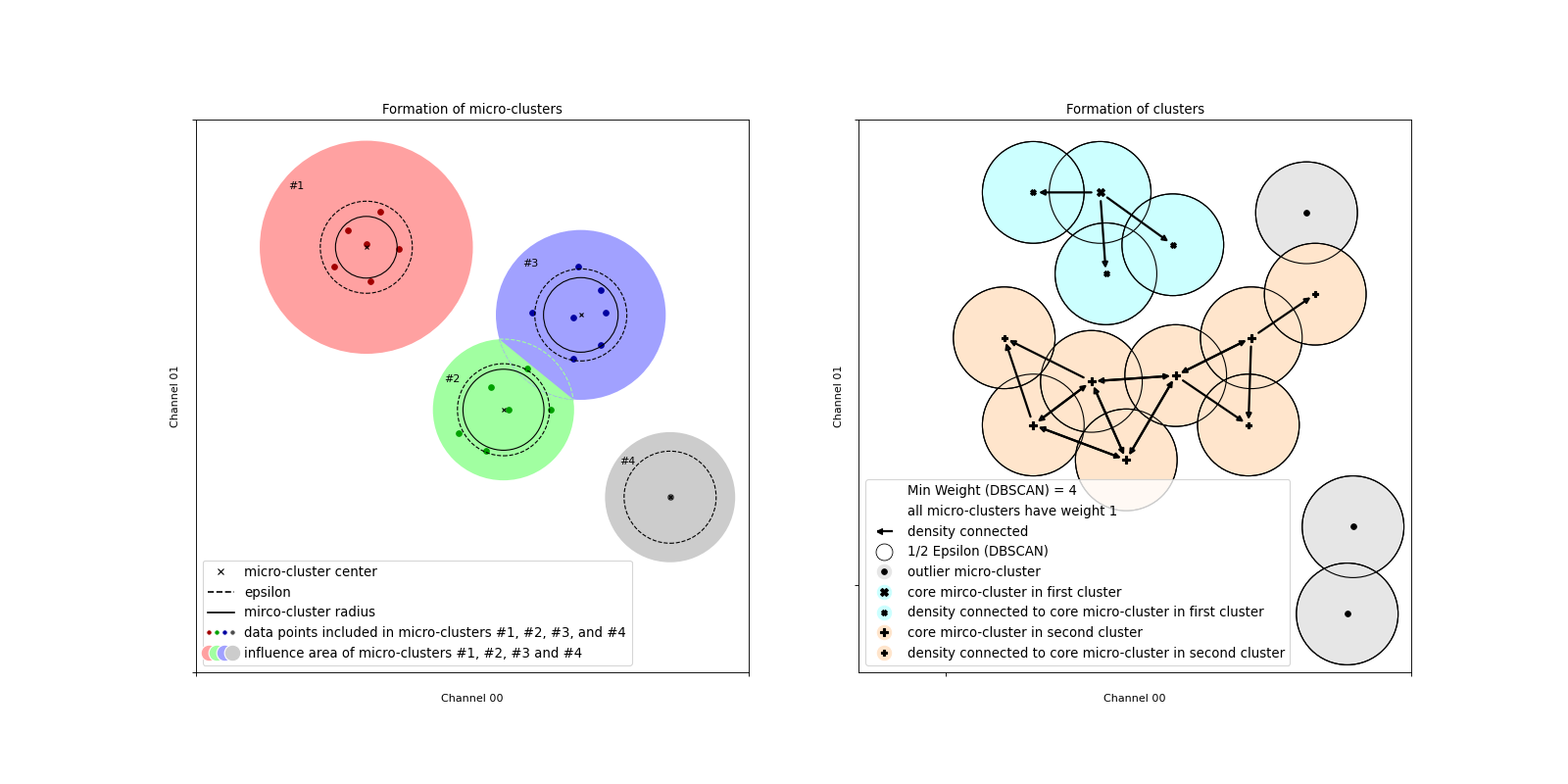
Im linken Plot der Abbildung ist die Zuordnung der Datenpunkte zu den Mikro-Clustern exemplarisch für zwei Eingangskanäle skizziert. Abgebildet sind 20 Datenpunkte, die vier verschiedenen Mikro-Clustern zugeordnet werden. Das erste Mikro-Cluster enthält sechs Datenpunkte (#1, rot markiert), das zweite (#2, grün markiert) auch sechs, das dritte (#3, blau markiert) enthält sieben und das vierte (#1, grau markiert) nur einen Datenpunkte. Farbig hinterlegt ist jeweils der Bereich um den Mittelpunkt der Mikro-Cluster in dem sich ein neuer Datenpunkt befinden müsste, um bei gegebenem Epsilon (markiert durch gestrichelte Linie) in das jeweilige Mikro-Cluster aufgenommen zu werden. Dieser Einflussbereich ist größer, wenn bereits mehrere Datenpunkte im Mikro-Cluster enthalten sind und diese eine geringere Streuung aufweisen (vergleiche z.B. Mikro-Cluster #1 und #2). Außerdem können sich die Einflussbereiche von mehreren Mikro-Clustern überschneiden, und sich durch ihre Existenz gegenseitig beeinflussen, siehe Mikro-Cluster #2 (grün) und #3 (blau). Die Datenpunkte werden stets dem näheren Mikro-Cluster zugewiesen, weshalb die Einflussbereiche durch eine gerade Linie abgetrennt sind. Im Plot ist ein Datenpunkt zu sehen, der Mikro-Cluster #2 zugeordnet ist, wenn dieses jedoch nicht existieren würde, dann wäre er Mikro-Cluster #3 zugeordnet.
Wie auch in der Originalarbeit [1] werden Mikro-Cluster abhängig von ihrem Gewicht in potenzielle und Ausreißer-Mikro-Cluster aufgeteilt. Nur potenzielle Mikro-Cluster werden anschließend vom DBSCAN-Algorithmus geclustert. Die Datenpunkte in den Ausreißer-Mikro-Clustern werden als Ausreißer gekennzeichnet. Aber auch Ausreißer-Mikro-Cluster werden gespeichert und durch neue Datenpunkte aktualisiert, da sie sich noch zu potenziellen Mikro-Clustern entwickeln können. Das Gewicht eines Mikro-Clusters muss die Schwelle Beta x Mu überschreiten, um als potenzielles Mikro-Cluster gezählt zu werden. In der linken Skizze der Abbildung enthält das Mikro-Cluster #4 (grau) zum Beispiel nur einen Datenpunkt, hat damit ein Gewicht kleiner oder gleich eins und würde für Beta x Mu = 1 als Ausreißer-Mikro-Cluster gezählt werden.
Wenn eine Fading-Funktion angewendet wird, nimmt das Gewicht der Mikro-Cluster mit der Zeit ab. Diese Fading-Rate wird durch den Parameter Lambda festgelegt. Wenn der Wert auf null gesetzt wird, wird keine Fading-Funktion angewendet, anderenfalls nehmen die Gewichte jede Sekunde um einen Faktor von 2^(-Lambda) ab. Wenn das Gewicht eines Ausreißer-Mikro-Clusters unter eine interne Schwelle fällt (abhängig von Mu x Beta und Lambda), wird er aus dem Speicher gelöscht.
Die Parameter Epsilon (DBSCAN) und Min Weight (DBSCAN) betreffen die zweite Phase. Diese Parameter wurden vom DBSCAN-Algorithmus [3] übernommen.
Der DBSCAN-Algorithmus läuft über den Satz potenzieller Mikro-Cluster und weist ihnen Cluster-Bezeichnungen zu. Dies kann entweder der Index des Clusters, zu dem sie gehören, oder die Bezeichnung Ausreißer sein. Dem gegenwärtig verarbeiteten Datenpunkt wird dann die Bezeichnung des Mikro-Clusters, zu dem er gehört, zugeordnet.
Wie clustert DBSCAN die Mikro-Cluster? Der Algorithmus arbeitet nach dem Konzept der Dichte-Erreichbarkeit. Objekte (in diesem Fall Mikro-Cluster) gehören zu demselben Cluster, wenn sie dichte-verbunden sind. Das bedeutet, dass es eine Kette von Mikro-Clustern mit einem maximalen Abstand Epsilon (DBSCAN) geben muss. Alle Mikro-Cluster, die diese Kette bilden, müssen eine zweite Bedingung erfüllen. Die Summe der Gewichte aller Mikro-Cluster innerhalb des Abstands Epsilon (DBSCAN) um jedes einzelne Mikro-Cluster in dieser Kette muss die Schwelle Min Weight (DBSCAN) überschreiten. Mikro-Cluster, die nicht mit mindestens einem Mikro-Cluster dichte-verbunden sind, welches diese zweite Bedingung erfüllt, werden als Ausreißer gekennzeichnet.
Dies ist in der rechten Skizze der Abbildung dargestellt. Zur Vereinfachung wird hier angenommen, dass die Gewichtung aller Mikro-Cluster gleich 1 ist. Dies entspricht dem Fall, dass in jedem Mikro-Cluster genau ein Datenpunkt enthalten ist und keine Fading-Funktion angewendet wurde. Die beiden Cluster (markiert mit einem „x“ (türkis) und einem „+“ (orange)) mit den zwei Ausreißer-Mikro-Clustern ergeben sich, wenn der Parameter Min Weight (DBSCAN) auf vier gesetzt ist. Die mit einem großen „x“ bzw. „+“ markierten Mikro-Cluster sind Core-Mikro-Cluster. Das heißt mindestens drei weitere Mikro-Cluster (plus das betrachtete Mikro-Cluster = 4) haben eine maximale Distanz von Epsilon (DBSCAN) zu diesen Mikro-Clustern. Die mit einem kleinen „x“ bzw. „+“ markierten Mikro-Cluster sind keine Core-Mikro-Cluster, aber befinden sich in der Epsilon (DBSCAN) – Nachbarschaft eines Core-Mikro-Clusters und gehören somit zum selben Cluster. Das mit einem kleinen Punkt markierte Mikro-Cluster in der rechten, oberen Ecke ist ein Ausreißer-Mikro-Cluster. Es befindet sich zwar in der Epsilon (DBSCAN) – Nachbarschaft eines Mikro-Clusters, welches zu einem Cluster gezählt wird, dieses ist jedoch kein Core-Mikro-Cluster.
Genauso sind die beiden Mikro-Cluster rechts unten Ausreißer. Diese befinden sich zwar in unmittelbarer Epsilon (DBSCAN) – Nachbarschaft, jedoch sind sie nur zu zweit. Die Schwelle Min Weight (DBSCAN) der Gewichte wird nicht überschritten.
Die Parameter outMCs Buffer Size und potMCs Buffer Size sind spezifisch für diese Implementierung des Algorithmus und erforderlich, weil der Speicher für Ausreißer und potenzielle Mikro-Cluster vor der Ausführung zugewiesen werden muss. Somit begrenzen outMCs Buffer Size und potMCs Buffer Size die mögliche Anzahl der Ausreißer und potenziellen Mikro-Cluster während der Laufzeit. Der Benutzer muss solche Werte für diese Parameter finden, dass diese Grenze nicht überschritten wird.
Die maximale Anzahl der Ausreißer und potenziellen Mikro-Cluster während der Ausführung des Algorithmus hängt von der Verteilung der Eingangsdaten, aber auch von der Einstellung der anderen Parameter ab. Es gibt weniger Mikro-Cluster bei höheren Werten von Epsilon, da dies zu gröberen Mikro-Clustern führt, die Datenpunkte aus einem größeren Bereich enthalten können. Im Allgemeinen steigt die Anzahl der Ausreißer-Mikro-Cluster am Anfang der Analyse, sinkt jedoch wieder, wenn Ausreißer-Mikro-Cluster in potenzielle Mikro-Cluster übergehen. Wenn sich die Muster im Datenstrom mit der Zeit nicht verändern, pendelt sich die Anzahl der Mikro-Cluster nach einer Anfangsphase ein.
Je mehr Mikro-Cluster vorhanden sind, desto höher sind die Rechenanforderungen. Für alle Ausreißer und potenzielle Mikro-Cluster wir die Distanz zu einem Datenpunkt verglichen und anschließend müssen alle potenziellen Mikro-Cluster in die Berechnung des DBSCAN-Algorithmus einbezogen werden. Es muss also ein Kompromiss zwischen Rechengeschwindigkeit und der Grobheit der Mikro-Cluster eingegangen werden.
Was geschieht, wenn die Werte von outMCs Buffer Size und potMCs Buffer Size zu niedrig gesetzt sind und zu irgendeinem Zeitpunkt während der Analyse mehr Mikro-Cluster erforderlich sind, um die Eingangsdatenpunkte zu erfassen? Der Algorithmus ordnet in diesem Fall weiterhin die Datenpunkte den vorhandenen Mikro-Clustern zu und kennzeichnet die Datenpunkte entsprechend, aber die vorhandenen Mikro-Cluster werden nicht mehr aktualisiert, um einen Überlauf des Puffers zu verhindern. Dies bedeutet, dass das Clustern der Datenpunkte fortgesetzt wird, aber mit einem insgesamt stagnierten Merkmalsraum (älterer Satz von Mikro-Clustern). Änderungen im Muster des Datenstroms könnten nicht mehr erkannt werden.
[1] F. Cao, M. Ester, W. Qian, A. Zhou. Density-Based Clustering over an Evolving Data Stream with Noise. In Proceedings of the 2006 SIAM International Conference on Data Mining, S. 326-337. SIAM.
[2] M. Ester, H.-P. Kriegel, J. Sander und X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proc. of KDD, 1996.
[3] J. Sander, M. Ester, H.-P. Kriegel, X. Xu. Density-Based Clustering in Spatial Databases: The Algorithm GDBSCAN and its Applications. Data Mining and Knowlage Discovery 2, 169-194 (1998)
Syntax
Definition:
FUNCTION_BLOCK FB_ALY_DenStream
VAR_OUTPUT
ipResultMessage: Tc3_EventLogger.I_TcMessage;
bError: BOOL;
bNewResult: BOOL;
bConfigured: BOOL;
nClusterIdx: DINT;
nNumClusters: DINT;
fbTimeLastEvent: FB_ALY_DateTime;
fbTimeLastSwitch: FB_ALY_DateTime;
bOverflow: BOOL;
nNumPotMCs: UDINT;
nNumOutMCs: UDINT;
END_VAR Ausgänge
Ausgänge
Name | Typ | Beschreibung |
|---|---|---|
ipResultMessage | Beinhaltet nähere Informationen zum aktuellen Rückgabewert. Für diesen speziellen Schnittstellenzeiger ist intern sichergestellt, dass er immer gültig/zugewiesen ist. | |
bError | BOOL | Der Ausgang ist |
bNewResult | BOOL | Wenn ein neues Ergebnis berechnet wurde, ist der Ausgang |
bConfigured | BOOL | Zeigt |
nClusterIdx | DINT | Gibt den Cluster-Index an, den der DBSCAN-Algorithmus für den Datenpunkt des aktuellen Zyklus ausgibt. |
nNumClusters | DINT | Gibt die Gesamtzahl der vom DBSCAN-Algorithmus erkannten Cluster an. |
fbTimeLastEvent | FB_ALY_DateTime | Dies ist der Zeitstempel des letzten Zyklus mit einer Änderung des Cluster-Index |
fbTimeLastSwitch | FB_ALY_DateTime | Dies ist der Zeitstempel des letzten Zyklus mit einem Wechsel zwischen Aktualisierung und Nichtaktualisierung von Mikro-Clustern (entweder durch Setzen des Eingangs |
bOverflow | BOOL |
|
nNumPotMCs | UDINT | Gibt die Anzahl der gegenwärtig vorhandenen potenziellen Mikro-Cluster an. |
nNumOutMCs | UDINT | Gibt die Anzahl der gegenwärtig vorhandenen Ausreißer-Mikro-Cluster an. |
Beispiel
VAR
fbDenStream : FB_ALY_DenStream(nNumChannels := 2);
fbSystemTime : FB_ALY_GetSystemTime;
fEps : LREAL := 0.15;
fMuBeta : LREAL := 2;
fLambda : LREAL := 0;
fEps_DBSCAN : LREAL := 0.8;
fMinWeight_DBSCAN : LREAL := 2;
nPotMCsBufferSize : UDINT := 100;
nOutMCsBufferSize : UDINT := 100;
bConfigure : BOOL := TRUE;
nInputCh1 : UDINT;
fInputCh2 : LREAL;
bUpdateMCs : BOOL := TRUE;
END_VAR// Configure algorithm
IF bConfigure THEN
bConfigure := FALSE;
fbDenStream.Configure(
fEps := fEps,
fMuBeta := fMuBeta,
fLambda := fLambda,
fEpsDBSCAN := fEps_DBSCAN,
fMinWeightDBSCAN:= fMinWeight_DBSCAN,
nPotMCsBufferSize := nPotMCsBufferSize,
nOutMCsBufferSize := nOutMCsBufferSize);
END_IF
// Get current system time
fbSystemTime.Call();
// Call algorithm
fbDenStream.SetChannelValue(1, nInputCh1);
fbDenStream.SetChannelValue(2, fInputCh2);
fbDenStream.Call(tTimestamp := fbSystemTime.tSystemTime, bUpdateMCs := bUpdateMCs);
Voraussetzungen
Entwicklungsumgebung | Zielplattform | Einzubindende SPS-Bibliotheken |
|---|---|---|
TwinCAT v3.1.4024.0 | PC oder CX (x64, x86) | Tc3_Analytics |
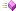 Methoden
Methoden
Name | Definitionsort | Beschreibung |
|---|---|---|
Call() | Local | Methode zur Berechnung der Ausgänge für eine bestimmte Konfiguration. |
Configure() | Local | Allgemeine Konfiguration des Algorithmus mit seinen parametrisierten Bedingungen. |
FB_init() | Local | Initialisieren der Anzahl der Eingangskanäle. |
Reset() | Local | Setzt alle internen Zustände oder die bisher durchgeführten Berechnungen zurück. |
SetChannelValue() | Local | Methode zur Übergabe von Werten an den Algorithmus. |