Support vector machine
A support vector machine (SVM) can be used both for classification and for regression. The SVM is a frequently used tool in particular with regard to classification tasks.
The fundamental goal of an SVM is to find a hyperplane in an N-dimensional space, wherein the distance between the closest data point and the plane is maximized. A hyperplane can only separate the space linearly (also called linear SVM). A non-linear separation is also possible by means of a so-called kernel trick (also called kernel SVM). The N-dimensional space is transformed into a higher-dimensional space here. A linear separation with a hyperplane is possible in an accordingly higher-dimensional space.
If a distinction needs to be made between several classes, several support vector machines are generated internally and classification takes place by means of comparisons. A one-class SVM can also be trained and used for anomaly detection.
Supported properties
ONNX support
The following ONNX operators are supported:
- SVMRegressor
- SVMClassifier
Supported kernel functions are listed in the following table:
Kernel function | Description |
|---|---|
Linear |
|
Radial Basis Function (RBF) |
|
Sigmoid |
|
Polynomial |
|
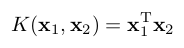
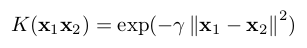
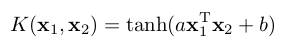
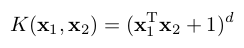
For samples of the export of SVMs as ONNX, see ONNX export of an SVM.
 | Classification limitation With classification models, only the output of the labels is mapped in the PLC. The scores/probabilities are not available in the PLC. |
Supported data types
A distinction must be made between "supported datatype" and "preferred datatype". The preferred datatype corresponds to the precision of the execution engine.
The preferred datatype is floating point 64 (E_MLLDT_FP64-LREAL).
When using a supported datatype, an efficient type conversion automatically takes place in the library. Slight losses of performance can occur due to the type conversion.
A list of the supported datatypes can be found in ETcMllDataType.