Configure Mode
Dieses Kapitel ist eine Zusammenstellung aller nötigen Informationen, um den Konfigurationsmodus (Configure Mode) des TwinCAT Database Servers zu nutzen. Es behandelt folgende Themen:
- Erstellen eines Projektes
- Anlegen und Einstellen einer Datenbankkonfiguration
- Anlegen und Einstellen von Autologgruppen
- Aktivieren eines Database-Server-Projektes
- Überwachen und Steuern des automatischen Loggens
Configure Mode
Im Configure Mode ist der Hauptteil der Arbeit im Konfigurator zu verrichten. Hier muss die Konfiguration für die gewünschte Datenbank und für die AutoLog-Gruppe eingestellt werden. Für die Konfiguration der AutoLog-Gruppe kann der Target Browser genutzt werden, um online auf ein Zielsystem zuzugreifen und die zu kommunizierenden Variablen auszuwählen. Nutzt der Anwender die Option AutoStart, so wird die Kommunikation mit der konfigurierten Datenbank direkt mit dem Aufstarten des TwinCAT-Systems aufgenommen. Wird die Option Manual gewählt, muss die Kommunikation durch den Funktionsbaustein FB_PLCDBAutoLog oder für den Autolog View angesteuert werden.
Projekt erstellen
Durch die TwinCAT-Connectivity-Erweiterung für Visual Studio steht eine neue Projektvorlage zur Verfügung. Beim Erstellen eines neuen Projektes erscheint nun die Kategorie TwinCAT Connectivity Project in der Auswahl.
Um ein neues TwinCAT-Connectivity-Projekt zu erstellen, wählen Sie das Empty TwinCAT Connectivity Project, legen den Projektnamen und den Speicherort fest und fügen es mit OK der Solution hinzu. TwinCAT-Connectivity-Projekte bzw. TwinCAT-Database-Server-Projekte können so komfortabel neben TwinCAT- oder anderen Visual-Studio-Projekten angelegt werden.
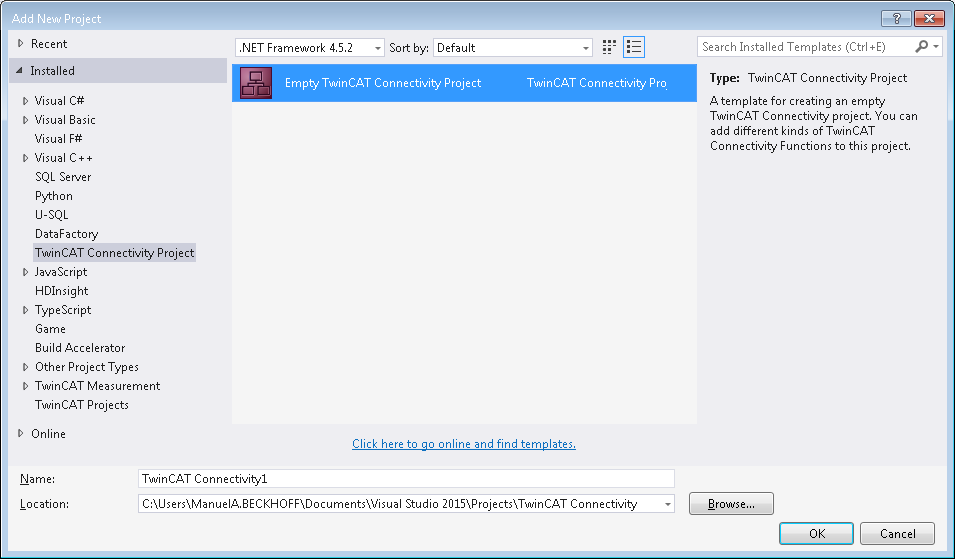
In der Solution erscheint ein neuer Projektknoten. Unterhalb des Connectivity-Projektknotens können Sie Subprojekte der unterstützten Connectivity-Funktionen ergänzen.
Mit Add können Sie dem TwinCAT-Connectivity-Projekt ein neues TwinCAT-Database-Server-Projekt hinzufügen. Das TwinCAT-Database-Server-Projekt befindet sich in der Auflistung der vorhandenen Item Templates.
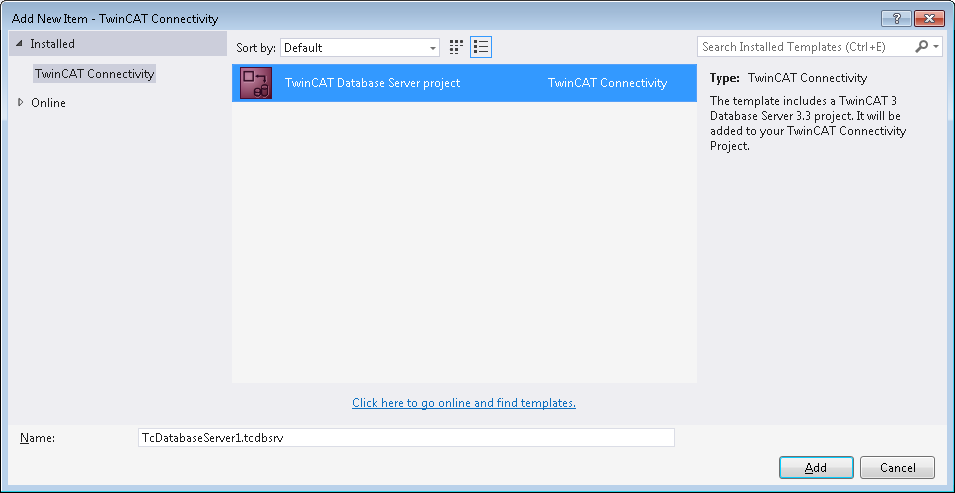
Unterhalb des TwinCAT-Connectivity-Knotens wird ein neues TwinCAT-Database-Server-Projekt angelegt.
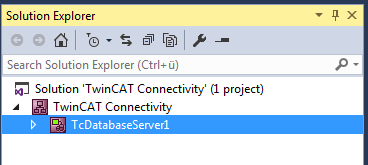
Dieses dient nun als Basis für die anstehende Konfiguration eines TwinCAT Database Servers. Das Dokument können Sie sowohl über die Eigenschaften im Eigenschaftsfenster, als auch über einen Editor bearbeiten.
Einem Connectivity-Projekt können Sie beliebig viele TwinCAT-Database-Server-Projekte oder andere Projekte hinzufügen, und damit auch mehrere Konfigurationen in einem Connectivity-Projekt einstellen.
Editor für Server-Einstellungen
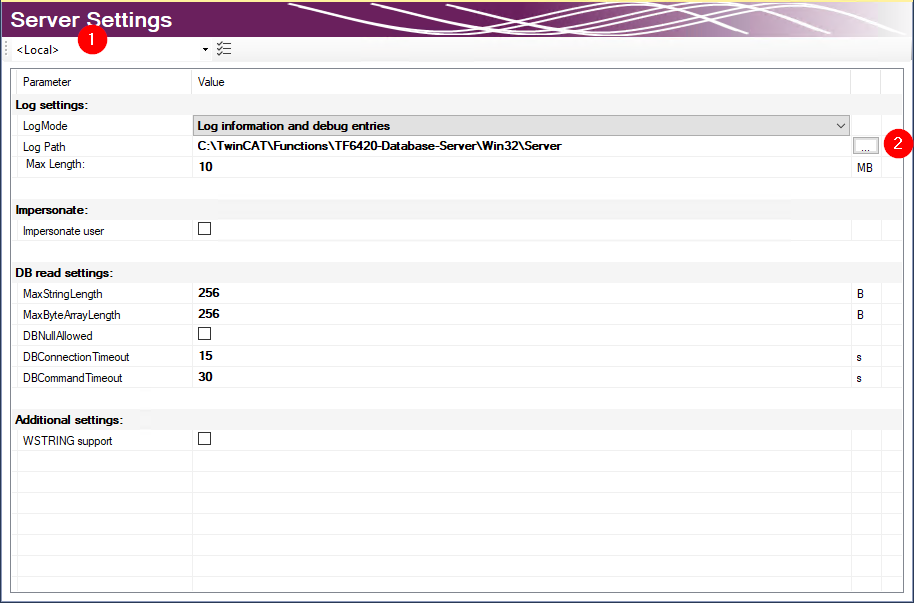
Im Editor Server Settings können Sie die Einstellungen für den TwinCAT Database Server bearbeiten. Diese Einstellungen betreffen den entsprechenden Server im Allgemeinen. Im Drop‑down‑Menü (1) können Sie das Zielsystem über die Ams-NetId angegeben. Dafür müssen Sie über TwinCAT eine Route zum Zielsystem anlegen. Wird eine fertige Konfiguration übertragen, werden die Einstellungen auf den TwinCAT Database Server dieses Zielsystems gespeichert.
In den Log settings konfigurieren Sie Einstellungen zum Aufzeichnen von Fehlerfällen. In einem Fehlerfall erzeugt der Database Server einen detaillierten Eintrag in einer Logdatei. Diese können Sie mit dem Information Log Viewer auslesen. In den Log Settings geben Sie einen Pfad zum Ablageort und die maximale Größe der Datei an. Zusätzlich können Sie die Genauigkeit des Logs beeinflussen. Wir empfehlen, aus Performancegründen, das Loggen nach erfolgter Fehleranalyse wieder abzuschalten, wenn es nicht mehr benötigt wird.
Bei Netzwerkzugriff auf dateibasierende Datenbanken wie Access Datenbanken oder SQL Compact Datenbanken müssen Sie die Option Impersonate setzen, damit sich der TwinCAT Database Server mit dem Netzwerklaufwerk verbinden kann. Diese Funktion wird zurzeit nicht unter Windows CE unterstützt.
Sie können weitere Einstellungen konfigurieren, um das Lesen aus der Datenbank zu steuern. Diese Einstellungen beziehen sich auf den TwinCAT Database Server auf dem Zielsystem:
MaxStringLength | Maximale String-Länge der Variablen in der SPS |
MaxByteArrayLength | Maximale Byte-Array-Länge der Variablen in der SPS |
DBNullAllowed | Gibt an, ob NULL-Werte im TwinCAT Database Server angenommen werden. |
DBConnectionTimeout | Gibt die Zeit an, wann der TwinCAT Database Server bei einem Verbindungsaufbau von einem Verbindungsfehler ausgeht. |
DBCommandTimeout | Gibt die Zeit an, wann der TwinCAT Database Server bei einem abgesendeten Kommando von einem Verbindungsfehler ausgeht. Bei hohen Datenmengen kann, je nach Datenbank und Infrastruktur ein Befehl durchaus sehr viel Zeit in Anspruch nehmen. |
Unterstützte Datenbanktypen
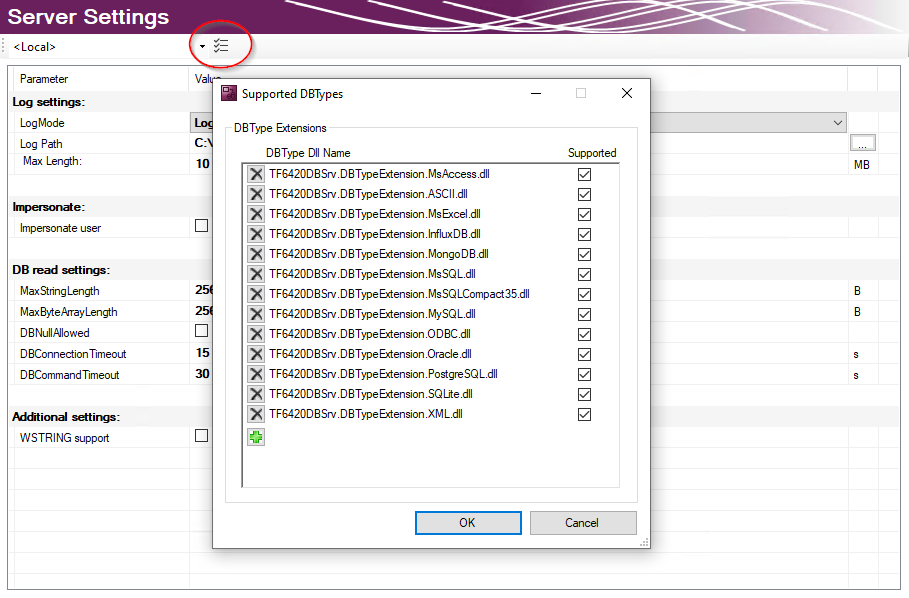
Die installierten Datenbanktypen können in den Server Einstellungen ausgewählt werden. Standardmäßig sind alle installierten Datenbanken angewählt. Der TwinCAT 3 Database Server wird die entsprechenden Datenbankschnittstellen laden. Auf diese Weise können nicht genutzte Datenbanken auf dem Zielsystem abgewählt werden.
Eine neue Datenbankkonfiguration hinzufügen
Die Datenbankkonfiguration wird benötigt, um dem Database Server alle nötigen Informationen zur Datenbankverbindung mitzuteilen.
Eine neue Datenbankkonfiguration können Sie mithilfe des Kommandos Add new Database über das Kontextmenü eines Database-Server-Projektes oder das entsprechende Kommando in der Toolbar hinzufügen.
Eine neue Datenbankkonfiguration wird als Datei auf im Projektordner hinzugefügt und in das Projekt eingebunden. Wie bei allen Visual-Studio-Projekten, werden die Informationen über die neuen Dateien im Connectivity-Projekt hinterlegt.
Editor für Datenbankkonfigurationen
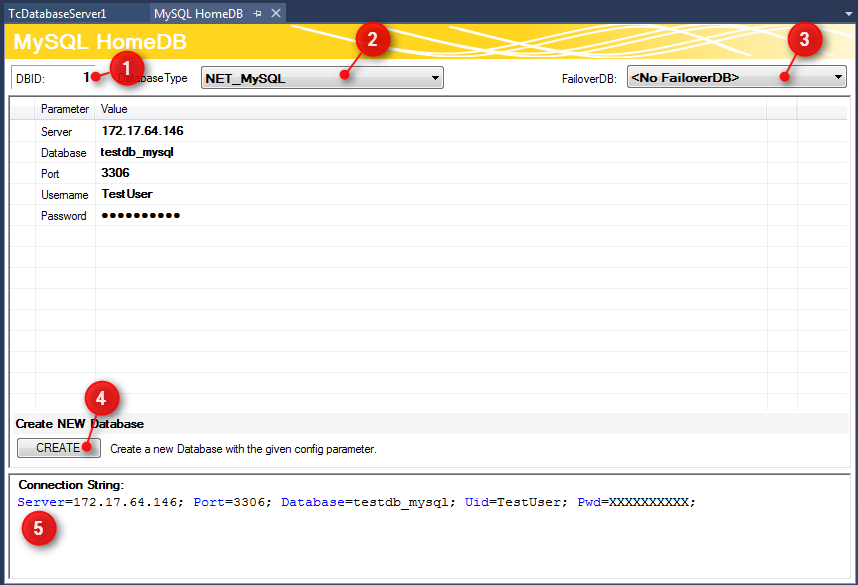
Im oberen Teil des Editors wird die Datenbank ID angezeigt (1), die für einige Funktionsbausteine in der SPS benötigt wird. Den Datenbanktyp der Zieldatenbank können Sie aus dem Drop-down-Menü auswählen (2). Hier können Sie auch die Odbc-Schnittstelle für eine Datenbank nutzen, die noch nicht unterstützt wird. Beachten Sie, dass je nach Datenbank nicht alle Funktionen des TwinCAT Database Servers gewährleistet werden.
Außerdem können Sie optional eine sogenannte FailOver-Datenbank (3) auswählen, welche im ‚Configure‘-Mode beim Fehlerfall einspringt. Bei einem Verbindungsabbruch zum Netzwerk kann in einem solchen Fall automatisch gewährleistet werden, dass keine Daten verloren gehen und an anderer Stelle gespeichert werden.
Für jede Datenbank stehen zusätzlich weitere einstellbare Parameter zur Verfügung. Je nach Datenbank wird ein Connection String (5) erstellt, welcher die Verbindung zur Datenbank beschreibt. Diese Anzeige dient zur Transparenz Ihrer eingestellten Parameter.
Über die Schaltfläche CREATE (4) können Sie eine neue Datenbank erstellen. Diese Funktion wird nur angezeigt, wenn sie von der jeweiligen Datenbank unterstützt wird.
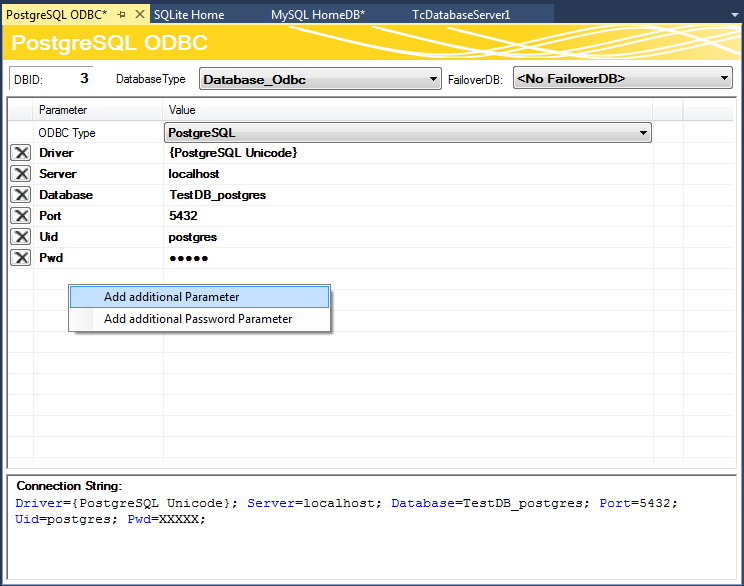
Sie können auch unbekannte Datenbanken mit einer ODBC-Schnittstelle konfigurieren. Dafür wählen Sie im in der Drop-down-Liste ODBC Type den Eintrag „Unknown Database“ und fügen über die Befehle im Kontextmenü Parameter hinzu. Diese können auch Passwörter beinhalten, welche dann verschlüsselt abgespeichert werden. Daraus kann der gewünschte Connection String zusammengestellt werden. Beachten Sie, dass nur begrenzte Funktionen des TwinCAT Database Servers genutzt werden können. Nur die expliziten Funktionsbausteine des SQL Expert Modes werden unterstützt.
 | Failover Datenbank Der TwinCAT 3 Database Server verfügt über die Funktion von Failover Datenbanken. Diese Funktion bietet die Möglichkeit, um bei Verbindungsverlust oder anderen Problemen mit der eingerichteten Datenbank auf eine andere Datenbank umzusteigen, um möglichen Datenverlust zu vermeiden. Diese Funktion wird nur vom ‚Configure Mode‘ unterstützt. Beim automatischen Wegschreiben, wird im Fehlerfall die entsprechend andere Datenbank genutzt. Die Tabelle der ersten Datenbank muss dafür der zweiten gleichen. |
Eine neue Autologgruppe hinzufügen
In den Autologgruppen befinden sich die Informationen, welche Variablen der SPS mit welchen Variablen aus den Datenbanken synchronisiert werden sollen. Zusätzlich werden hier Informationen über die Synchronisationszeitpunkte und der Art der Synchronisation hinterlegt.
Eine neue AutoLog-Gruppe für die Datenbankkonfiguration können Sie mithilfe des Kommandos Add new AutologGroup im Kontextmenü einer Datenbankkonfiguration oder über die Toolbar hinzufügen. Diese AutoLog-Gruppen beziehen sich auf die übergeordnete Datenbank.
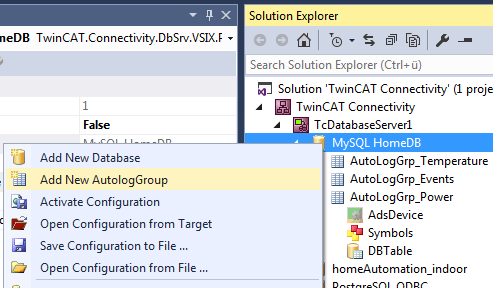
Eine neue AutoLog-Gruppe sowie die dazugehörigen Komponenten werden als Dateien im Projektordner hinzugefügt und im Projekt eingebunden. Dazu gehören das Ads Device, die Symbolgruppen und die Tabelleneinstellungen. Um diese Dateien im Projekt zu speichern, sollten Sie die TwinCAT-Connectivity-Projektdatei speichern. Diese Dateien können Sie dann in Editoren oder im Eigenschaftenfenster bearbeiten.
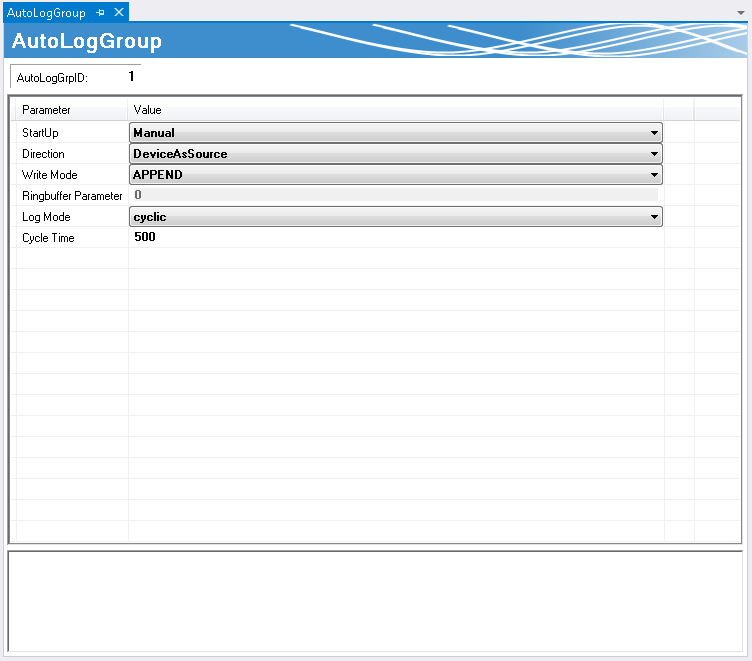
StartUp | Der AutoLog-Modus kann über den manuellen Weg (durch einen Befehl in der SPS oder aus dem Konfigurator) oder automatisch beim Systemstart eingeschaltet werden. |
Direction | Das eingestellte ADS-Gerät dient als Datenziel oder als Datenquelle. |
Write Mode | Die Daten können in einer Datenbank zeilenweise angehängt, auf zeitlicher Basis oder nach Anzahl in einem Ringpuffer gehalten oder einfach an der entsprechenden Position aktualisiert werden. |
Ringbuffer Parameter | Je nach Einstellung stellt dieser Parameter die Zeit oder die Zyklen dar, nach der der Ringbuffer aktualisiert wird. |
Log Mode | Entweder wird die Variable nach Ablauf eines gewissen Zyklus oder auf Änderung geschrieben. |
Cycle Time | Zykluszeit, nach welcher die Variable geschrieben wird. |
Ads Device konfigurieren
Das Ads Device wird automatisch unter eine AutoLog-Gruppe angelegt. Das Ads Device ist im häufigsten genutzten Anwendungsfall die SPS-Laufzeit. Folgende Einstellungen können im Editor getroffen werden:
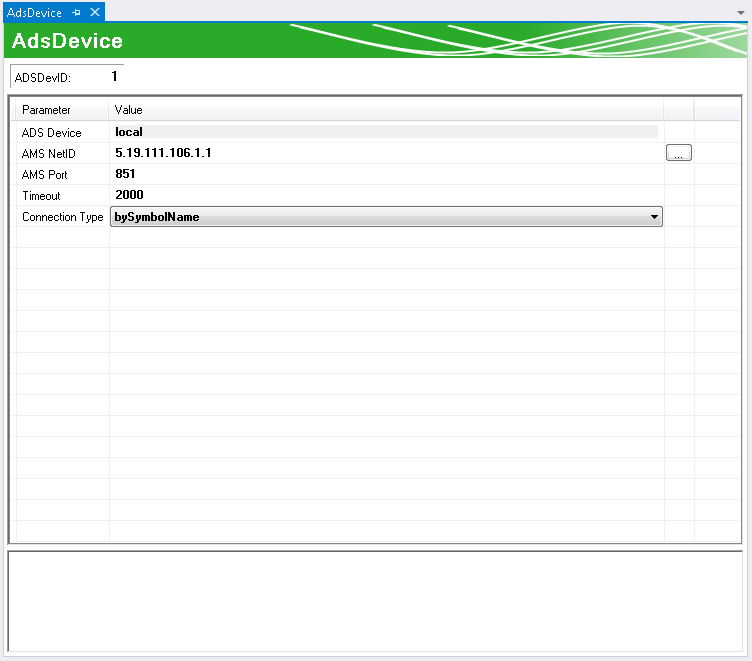
ADS Device | Bezeichnung des ADS-Zielgeräts. |
AMS NetID | Adresse des Zielgeräts im TwinCAT-Netzwerk. |
AMS Port | Port des Zielgeräts im TwinCAT-Netzwerk. |
Timeout | Zeit, nach der von einem Verbindungsabbruch zum Zielgerät ausgegangen wird. |
Connection Type | bySymbolName: Verbindung wird anhand des Namens des Symbols hergestellt. byIndexGroup: Verbindung wird anhand des Speicherindex hergestellt. |
Symbole konfigurieren
Je nachdem, ob das ADS-Gerät Datenziel oder Datenquelle ist, werden die Symbole, die Sie hier einstellen, in die Datenbank geschrieben oder aus der Datenbank ausgelesen. Für einen komfortablen Zugriff können Sie den TwinCAT Target Browser verwenden. Hier können die Symbole auf dem Target gesucht und per drag-and-drop zwischen den beiden Tools kommuniziert werden.
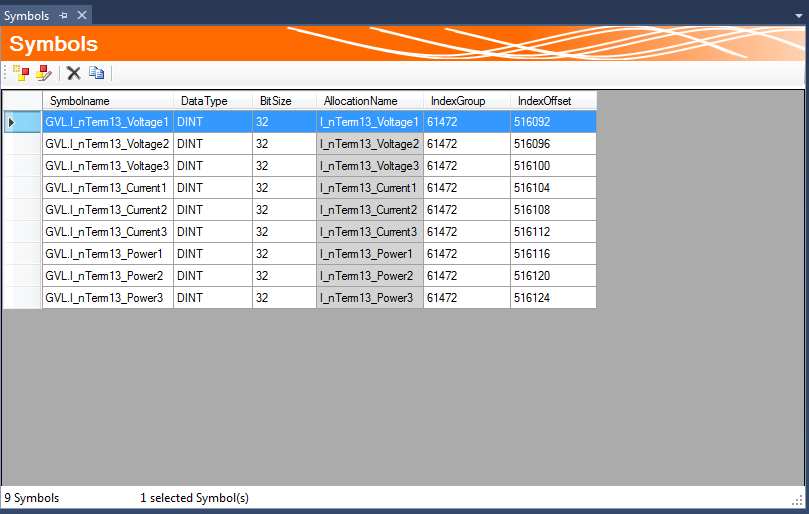
Sie könne Symbole auch manuell zur Symbolgruppe hinzufügen oder bearbeiten. Je nachdem, ob im ADS-Gerät der Verbindungstyp über die Symbolnamen oder die Index-Gruppen ausgewählt wurden, werden entsprechende Informationen benötigt. Dabei wird immer vom ADS-Gerät ausgegangen.
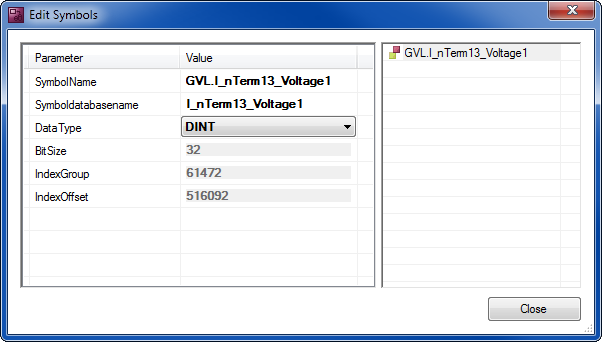
SymbolName | ausgehend vom einstellten ADS-Gerät wird das Symbol angesprochen |
Symboldatabasename | Name der Variable in der Datenbanktabelle |
DataType | SPS-Datentyp des Symbols |
BitSize | Bit-Größe des Symbols (wird bei automatisch für die Datentypen eingestellt) |
IndexGroup | Indexgruppe im TwinCAT-System |
IndexOffset | Indexoffset im TwinCAT-System |
Tabelle konfigurieren
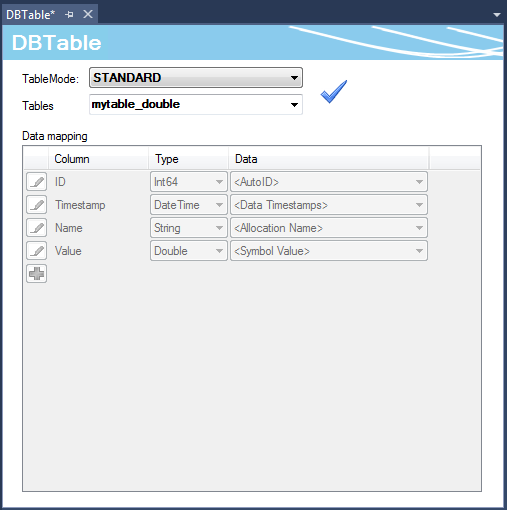
Die Tabelle in einer Datenbank kann nach einer Standardtabellenstruktur oder nach einer individuellen Struktur aufgebaut sein.
Die entsprechende Tabelle können Sie aus einer Liste möglicher Tabellen auswählen. Ist die Tabelle noch nicht vorhanden, können Sie diese mithilfe des SQL Query Editors erzeugen. Falls Sie die Standardtabellenstruktur auswählen, zeigt Ihnen ein blauer Haken an, ob die ausgewählte Tabelle dieser Struktur entspricht.
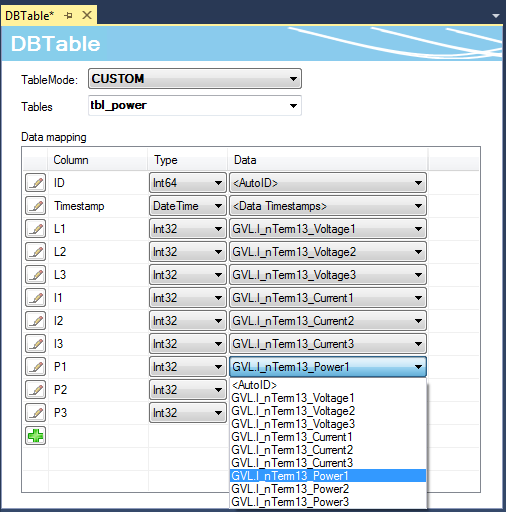
Der spezifische Tabellentyp bietet Ihnen die Möglichkeit, die einzelnen Symbole, welche in der Symbolgruppe eingestellt wurden, auf die Tabellenspalten in der Datenbank beliebig zu verteilen. Wird ein Datensatz nun während des AutoLog-Modus in die Datenbank geschrieben, werden die aktuellen Werte der Symbolgruppe zum Abtastzeitpunkt in der entsprechenden Spalte der Tabelle gespeichert.
Projekt aktivieren
Um ein konfiguriertes Projekt auf dem TwinCAT Database Server zu aktivieren, verwenden Sie im Kontextmenü des TwinCAT-Database-Server-Projektes das Kommando Activate Configuration.
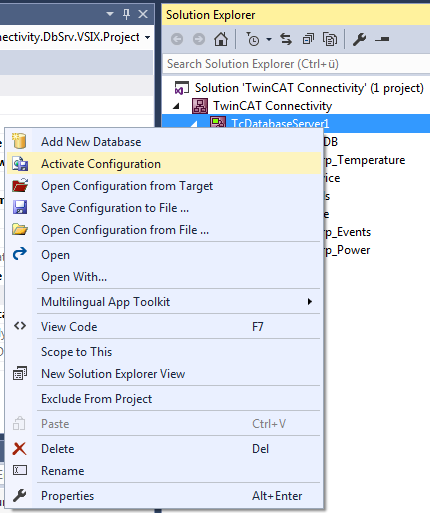
Je nachdem, welches Aufstartverhalten in der AutoLog-Gruppe angewiesen wurde, startet nun das Loggen der Variable mit dem Aufstarten des TwinCAT System. Manuell können Sie den Modus mithilfe des nachfolgenden AutologViewers oder mit dem entsprechenden Funktionsbaustein aus der SPS starten.
AutoLog Viewer
Der AutoLog Viewer des TwinCAT Database Server ist ein Tool, um den AutoLog-Modus zu steuern und zu überwachen. Ähnlich wie bei der TwinCAT SPS können Sie sich auf ein Zielsystem einloggen. Im eingeloggten Zustand kann der AutoLog-Modus gestartet oder gestoppt werden. Im unteren Bereich des Fensters werden Informationen über den aktuellen Zustands des Loggens mitgeteilt. Durch das Selektieren einer AutoLog-Gruppe werden weitere Informationen über die geloggten Symbole angezeigt.
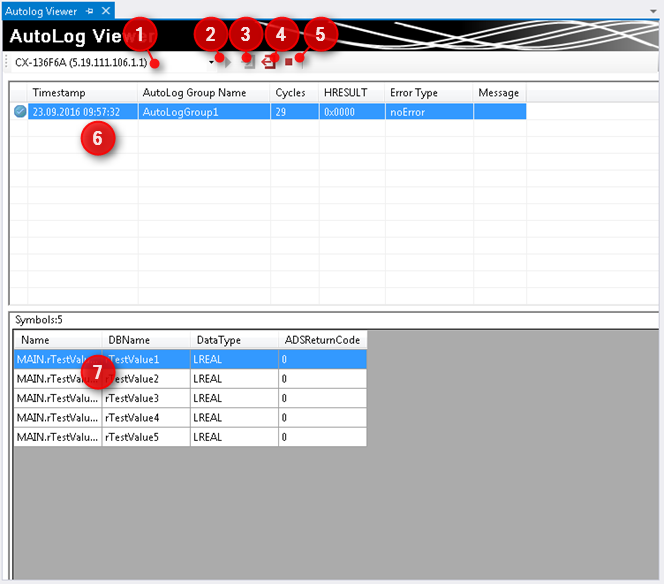
ID | Bezeichnung | Funktion |
|---|---|---|
1 | Zielsystem | Auswahl des Zielsystems mit installiertem TwinCAT Database Server |
2 | Start | Manueller Start des AutoLog-Modus |
3 | Einloggen | Einloggen auf den aktiven AutoLog-Prozess |
4 | Ausloggen | Ausloggen aus dem aktiven AutoLog-Prozess |
5 | Stopp | Manueller Stopp des AutoLog-Modus |
6 | Autologgruppen | Auflistung konfigurierter Autolog-Gruppen auf dem Zielsystem |
7 | Symbole | Auflistung konfigurierter Symbole der ausgewählten AutoLog-Gruppe |
Mit dem Autolog Viewer kann die konfigurierte Applikation gestartet und überwacht werden. Je nach Einstellung ist nach dem Einloggen und Starten der hochzählende Zykluszähler der AutoLog-Gruppen entsprechend der Aktualisierungszeiten sichtbar. Auch Fehler beim Aktualisieren können Sie hier feststellen. Zur detaillierteren Behandlung empfehlen wir den InformationLog View.
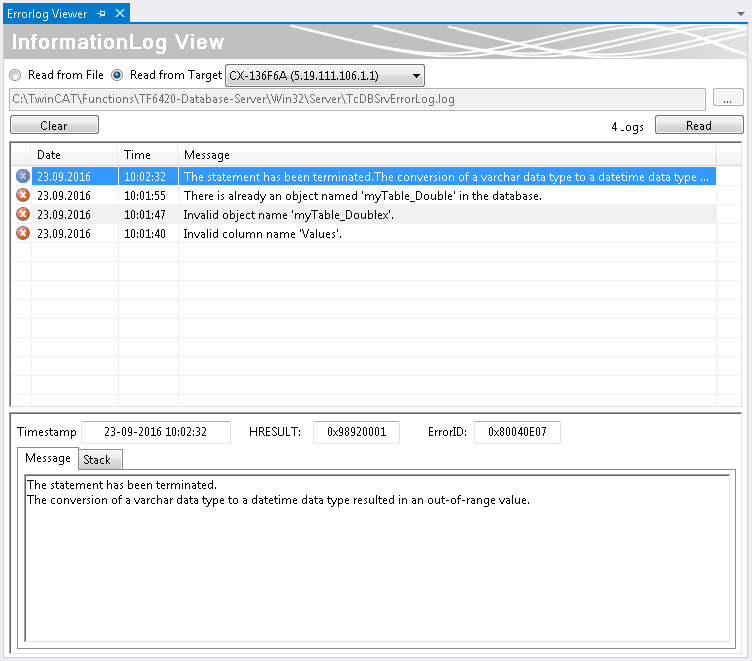
Nähere Fehlerbehandlung mit dem InformationLog View
Der InformationLog View ist ein Tool, um die Logdateien vom TwinCAT Database Server auszulesen. Protokollierte Informationen werden mit einem Zeitstempel, IDs und Fehlermeldungen im Klartext angezeigt.
Die Log-Dateien können nicht nur über den direkten Dateizugriff eingesehen oder geleert werden, sondern auch direkt über das Target. Gerade für verteilte Database Server im Netzwerk ist dies vorteilhaft, um einen schnellen und einfachen Zugriff auf die Logdatei zu erlangen. Für diesen Zugriff muss eine Route zum Zielgerät bestehen.