Modellbeschreibungsdateien auf Server-Device verfügbar machen
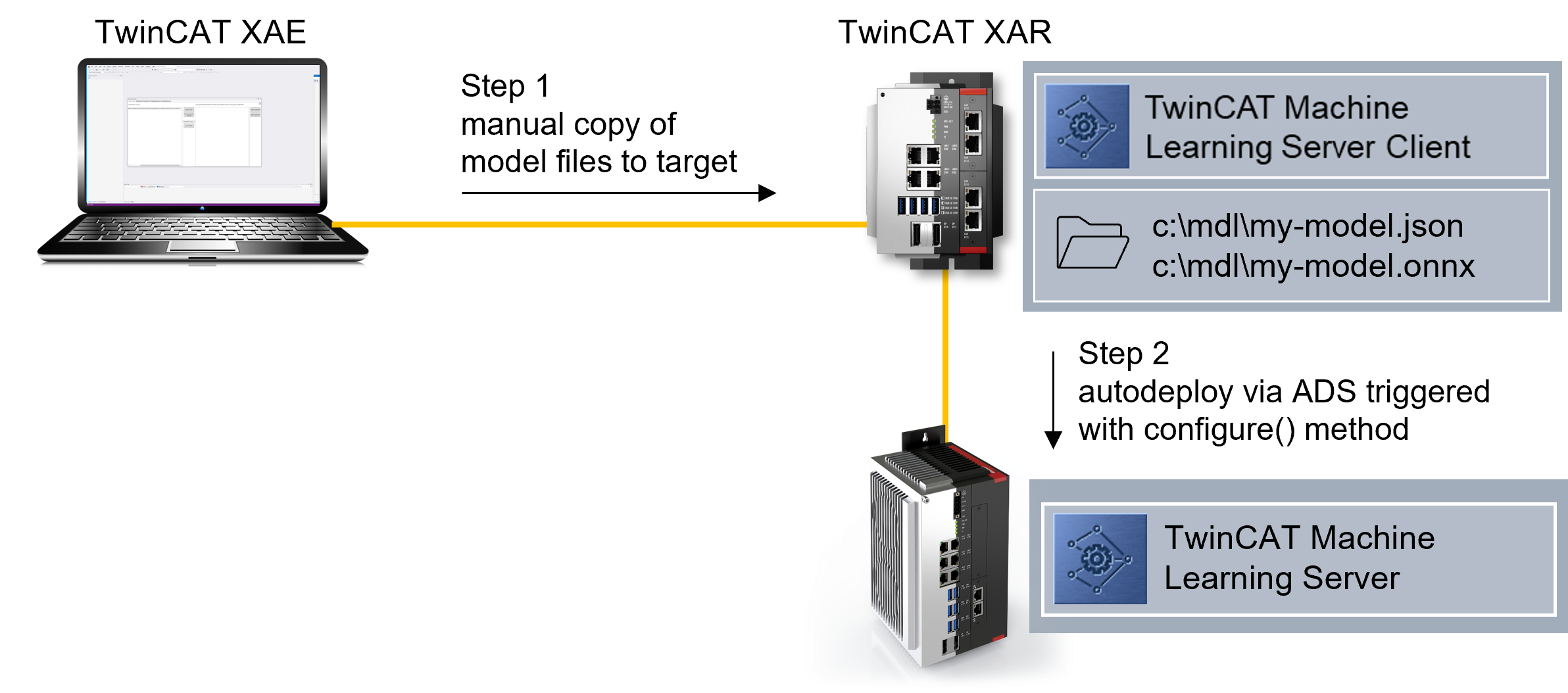
Um Modelle laden zu können, müssen diese dem TwinCAT Machine Learning Server bekannt gemacht werden. Das bedeutet, der Server muss den Ablageort der erstellten JSON- und ONNX-Datei auf dem Dateisystem kennen, um das KI-Modell erfolgreich laden zu können. Diese Bekanntmachung erfolgt über die Configure-Methode. Der Methode wird der Fullpath zur JSON-Datei übergeben, welche die Interface-Beschreibung trägt. Die zugehörige ONNX-Datei muss im gleichen Ordnerpfad abgelegt sein. Der Zusammenhang zwischen JSON und ONNX wird immer über einen Hash geprüft.
Die ONNX-Datei wird auf dem Gerät benötigt, auf dem der TwinCAT Machine Learning Server installiert ist. Die JSON-Datei wiederum wird auf dem Client-Gerät benötigt. Der Ablagepfad an sich ist frei wählbar; JSON und ONNX müssen aber den gleichen Pfad haben.
Variante 1 - Client und Server sind auf demselben IPC installiert: Die JSON- und ONNX-Datei sind auf dem IPC in einem beliebigen Pfad abzulegen.

Variante 2 - Client und Server sind auf unterschiedlichen IPCs installiert: Die ONNX-Datei kann direkt auf dem Server abgelegt werden. Die JSON-Datei ist dann auf dem Client-Gerät unter dem gleichen Pfad abzulegen.
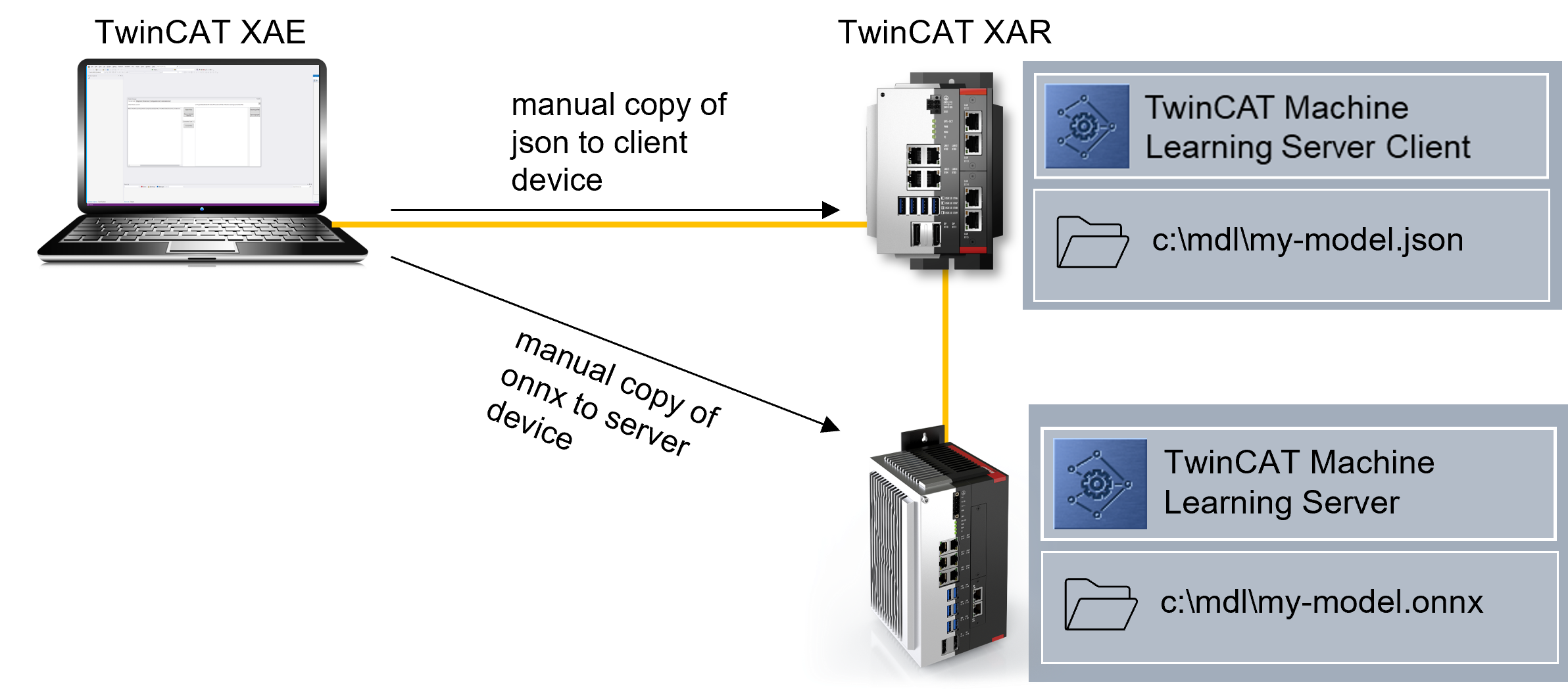
Variante 3 - Client und Server sind auf unterschiedlichen IPCs installiert: Die Modell-Dateien (ONNX und JSON) können alternativ beide auf dem Client abgelegt werden. Bei Aufruf der Configure-Methode wird zunächst der Pfad auf dem Server-Device geprüft. Wird die ONNX-Datei dort nicht gefunden, wird der Pfad auf dem Client-Device geprüft. Werden die JSON und ONNX auf dem Client-Device gefunden, wird die ONNX-Datei per ADS auf das Server-Gerät übertragen und dann vom Server geladen. Diese Variante ist zeitaufwändig und wird nur einmalig für dieses Modell durchgeführt. Danach wird das Modell direkt vom Server- Gerät geladen.
 | Der ADS-Router-Speicher muss groß genug sein, um das Modell über ADS verschicken zu können. |