Statistische Auswertung
Condition Monitoring wird zur Überwachung von Grenzwerten eingesetzt. Wertüberschreitungen verursachen Meldungen und Warnungen. In der Praxis schwanken die Einzelwerte der FFT oft stark, so dass eine Mittelung oder andere statistische Auswertung notwendig ist. Eine Auswertung von einzelnen Werten würde dazu führen, dass z.B. ein hoher Wert eine Überschreitung der Grenzwerte verursacht.
Grundbegriffe
Wird eine Größe (z.B. Temperatur, Druck, Spannung, …) in einem realen Prozess gemessen, wird bei wiederholter Messung mit sehr hoher Wahrscheinlichkeit der zuvor bestimmte Messwert nicht mit dem der wiederholten Messung übereinstimmen. Da sich der Verlauf von regellos schwankenden Größen nicht deterministisch (über eine konkrete Gleichung) beschreiben lässt, werden zur Beschreibung dieser Signale statistische Kenngrößen verwendet. Dabei ist es unerheblich, dass häufig eine Überlagerung von deterministischem und stochastischem Signal vorliegt (z.B. eine Gleichspannung überlagert mit Messrauschen). In Summe ist das Ergebnis zufällig und somit ein stochastisches Signal.
Eine einzelne Messung einer zufällig schwankenden Größe ist ein zufälliges Ereignis. Jede einzelne Messung wird als Realisierung aus einem Zufallsexperiment bezeichnet. Werden N Stichproben aus dem Zufallsexperiment gezogen, beschreibt diese Menge an Realisierungen den Stichprobenumfang.
Histogramme
Für zufällige Ereignisse ist eine zentrale Eigenschaft die Wahrscheinlichkeit, dass die gemessene Größe einen bestimmten Wert annimmt. Dies wird über die absolute oder relative Häufigkeitsverteilung beschrieben, welche in einem Histogramm dargestellt wird.
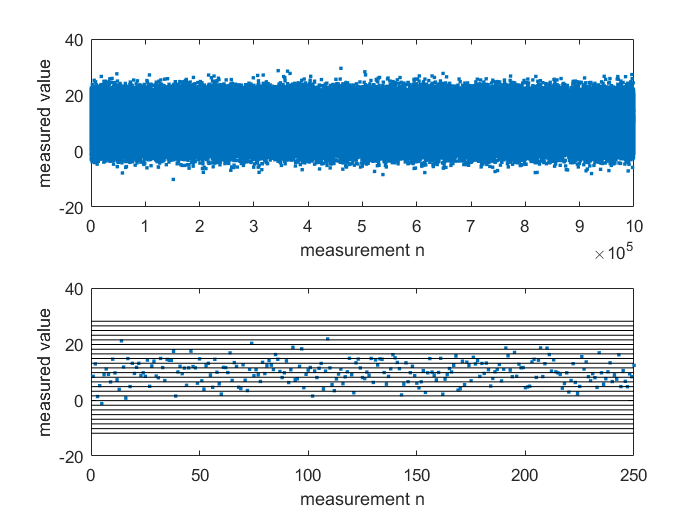
Einfaches Beispiel: Angenommen eine Messgröße von 10 Volt sei überlagert mit einem Normalverteilten Rauschen (Mittelwert 0 V und Standardabweichung 4 V). Wird der Messvorgang dieser Größe nun 1 Mio. Mal wiederholt, ergibt sich die untenstehende Grafik (oberer Teil). Die 1 Mio. Realisierungen des Zufallsexperiments können zur besseren Übersicht in einem Histogramm dargestellt werden. Die absolute Häufigkeitsverteilung kann so generiert werden, dass der Wertebereich der aufgenommenen Messgröße in Klassen (Bins) unterteilt wird. Im oberen Teil der Grafik ist die Messgröße über jede Einzelmessung aufgetragen, im unteren Teil sind nur die ersten 250 Messungen sowie die Klassengrenzen für das Histogramm gezeigt.
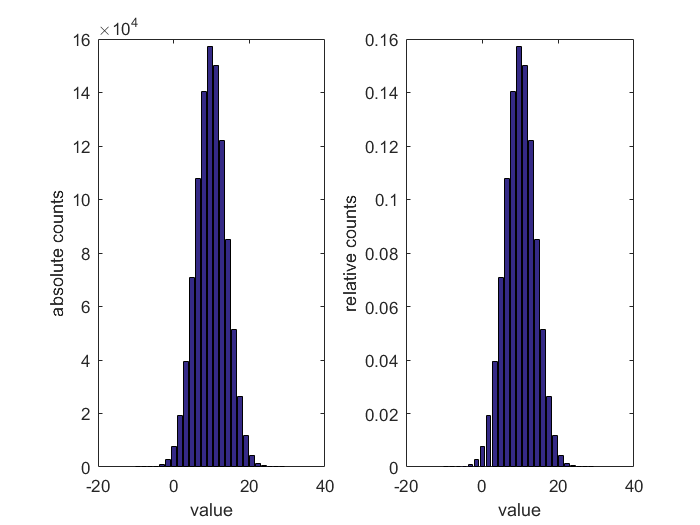
Die absolute Häufigkeitsverteilung ergibt sich dann ganz einfach aus der Anzahl von Messwerten die innerhalb einer Klasse (Bin) liegen, siehe folgende Grafik, links. Parametrisiert wird die Verteilung entsprechend durch die Anzahl der berücksichtigten Klassen – je mehr Klassen, desto feiner die Verteilung. Aus der absoluten Häufigkeitsverteilung kann durch Referenzieren auf den Stichprobenumfang die relative Häufigkeitsverteilung berechnet werden, siehe folgende Grafik, rechts. Diese ist dann unabhängig von der Anzahl der Messungen und zeigt die Wahrscheinlichkeit an, mit der ein Wert gemessen wurde, z.B. wurden Werte in der Klasse um 10 V mit einer Wahrscheinlichkeit von 0,157 = 15,7% gemessen.
Anhand einer Häufigkeitsverteilung lässt sich ein experimentell untersuchter Prozess zunächst visuell recht einfach einschätzen. Es können Fragen erörtert werden wie:
- Wie stark streut die Messgröße?
- Streut die Messgröße um einen Wert (wie oben um 10 V), oder streut die Messgröße auch um weitere Werte?
- Wie ist die Verteilung der Werte? - Normalverteilung, Student-t -Verteilung, Chi-Quadrat-Verteilung?
 | Berechnung der absoluten Häufigkeitsverteilung in TwinCAT 3 Mit der Condition Monitoring Bibliothek lässt sich die absolute Häufigkeitsverteilung einfach über den Funktionsbaustein FB_CMA_HistArray berechnen. Zur Parametrisierung des Bausteins werden lediglich der betrachtete Wertebereich und die Anzahl von Klassen benötigt. Eine grafische Darstellung ist mit dem Array-Bar-Chart im TwinCAT Scope View möglich. Dazu kann ein Sample heruntergeladen werden. |
Gewöhnliche und zentrale Momente
Aus einer gegebenen Stichprobe von zufällig schwankenden Größen kann ein Wert geschätzt werden, der dem wahren Wert möglichst nahe kommt – dieser wird als Schätzwert bezeichnet. Für diesen Vorgang kommen verschiedene Schätzer (z.B. der arithmetische Mittelwert) mit unterschiedlichen Eigenschaften in Frage. Neben der Berechnung eines Schätzwerts ist häufig auch eine Aussage über die Unsicherheit dieses Schätzwertes von Bedeutung, welcher i.d.R. über die Stichprobenstreuung (auch empirische Standardabweichung genannt) berechnet wird.
Zur Berechnung von statistischen Größen aus einer gegebenen Stichprobe eignen sich beispielsweise sehr gut die Momente: Mittelwert, Varianz, Schiefe, Kurtosis, … usw. Während der Mittelwert einen geeigneten Schätzwert der Stichprobe liefert, liefern die weiteren Momente Erkenntnisse über die Verteilung der Werte um diesen Schätzwert.
Erläuterung an einem Beispiel:
Die oben unter dem Punkt Histogramm beschriebene Stichprobe hat einen „wahren Wert“ von 10 V und wurde nachträglich verrauscht. Aus der gegebenen Stichprobe von 1 Mio. Realisierungen lässt sich der Mittelwert zu 9,9977 V berechnen und bildet den Schätzwert des wahren Werts. Die Varianz um diesen Mittelwert beträgt 16,01 V2. Die Wurzel aus der Varianz entspricht der Standardabweichung und beträgt 4,0013 V. Ist die Verteilung der Messwerte, wie in diesem Fall, Normalverteilt, ist die Verteilung der Messwerte mit diesen beiden Momenten komplett beschrieben, d.h. die Schiefe und Kurtosis sind (theoretisch) Null. Die Schiefe beschreibt die Symmetrie der Verteilung um den Mittelwert, hingegen beschreibt die Kurtosis die Steilheit (Spitzenhaltigkeit) einer Verteilungsfunktion.
Beurteilung der Unsicherheit eines Schätzergebnisses:
Das Joint Committee for Guides in Metrology (JCGM) hat 1995 einen Leitfaden zur Angabe der Unsicherheit beim Messen publiziert. Das JCGM setzt sich aus zentralen Dachverbänden wie dem BIPM, IEC; IFCC, ISO, usw. zusammen, die diesem gemeinsamen Leitfaden entwickelt haben. Das Basispapier „Guide to the Expression of Uncertainty in Measurement” – kurz GUM – kann z.B. auf den Seiten des BIPM frei heruntergeladen werden. Ein kurzer Einblick in die zentrale Idee wird im Folgenden gegeben.
Aus einer gegebenen Stichprobe mit N Werten lässt sich, wie oben beschrieben, ein Schätzwert (Mittelwert = Stichprobenmittelwert) berechnen. Als Unsicherheitsmaß wird nun nicht die Stichprobenstreuung (Standardabweichung = Streuung der Stichprobe) genutzt, sondern die Streuung des Stichprobenmittelwerts berechnet. Dies ist natürlich sinnvoll, denn es soll die Unsicherheit des Schätzwerts beurteilt werden und nicht die der Stichprobe. Die Streuung des Stichprobenmittelwerts lässt sich einfach aus der Stichprobenstreuung berechnen, indem dieser Wert durch die Wurzel aus N dividiert wird. Bei genügend großer Stichprobenmenge kann die Streuung des Stichprobenmittelwerts mit dem Faktor 2 (ansonsten größer) multipliziert werden, um die erweiterte Unsicherheit zu berechnen. Der Mittelwert plus/minus dieser erweiterten Unsicherheit enthält dann mit 95%-iger Wahrscheinlichkeit den wahren Wert der Messgröße.
Entsprechend ist es möglich mit den Algorithmen der Condition Monitoring Bibliothek GUM-konforme Aussagen über die Messunsicherheit zu liefern.
| Berechnung der Momente in TwinCAT 3 Mit der Condition Monitoring Bibliothek lassen sich mit dem Funktionsbaustein FB_CMA_MomentCoefficients die Momente erster bis vierter Ordnung (Mittelwert, Varianz, Schiefe, Kurtosis) einer Stichprobe berechnen. Der Baustein muss nur hinsichtlich der genutzten Stichprobenmenge parametrisiert werden. |
Quantile
Das p-Quantil Qp einer Zufallsvariablen x ist der Wert, für den Qp > x für den Anteil p aller Realisierungen von x ist. Etwas anschaulicher formuliert: Ist eine endliche Anzahl von Werten gegeben, so teilt das p-Quantil die Daten in zwei Bereiche ein. Das 50%-Quantil (auch Median) markiert z.B. den Wert unterhalb dessen mindestens 50% der in den Gesamtdaten vorkommenden Werte liegen. Dieser Wert ist nicht mit dem Mittelwert einer Stichprobe zu verwechseln.
Der Wert von p kann zwischen Null und Eins liegen. Wenn p in Prozent angegeben wird, handelt es sich um Perzentilen. So entspricht Q0.5 genau dem Median, während Q0.9 das 90-Prozent-Perzentil und Q1 das Maximum einer beobachteten Werte-Folge darstellt.
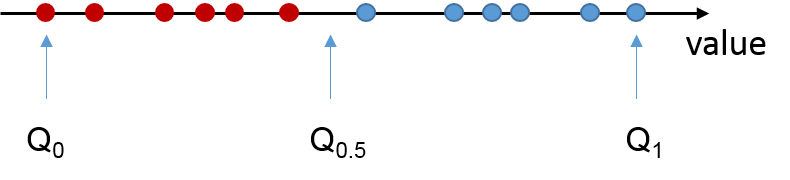
Je näher p an den Wert Eins heranrückt, desto stärker ist Qp durch Ausreißer und extreme Einzelwerte bestimmt, je näher umgekehrt p an den Wert 0.5 heranrückt, desto mehr nähert sich Qp dem Median an, welcher sehr robust gegenüber Ausreißern ist. Über den Wert von p, der in TwinCAT zur Laufzeit konfiguriert werden kann, lässt sich die Empfindlichkeit der Auswertung einer Stichprobe gegenüber von Einzelwerten dynamisch verändern.
Zur Veranschaulichung des Grundgedankens von Quantilen, zeigt folgende Grafik eine Folge von 1000 Werten, welche um einem Mittelwert von 13 streuen.
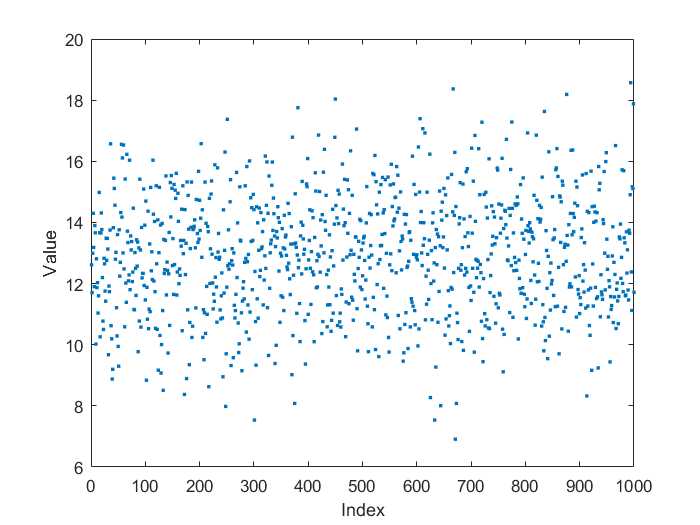
Aus der Wertfolge lässt sich das Histogramm berechnen, welches angibt wie häufig ein Wert in der betrachteten Folge (Stichprobe) vorkommt. Durch Integration der im Histogramm dargestellten absoluten Häufigkeit und Referenzieren auf die Gesamtzahl der Werte in der betrachteten Folge (hier 1000), kann die empirische Summenhäufigkeitsverteilung berechnet werden, anhand derer die Quantile leicht abzulesen sind. In diesem Fall liegt z.B. das 25%-Quantil bei 11.8, d.h. mindestens 25% der Einzelwerte der betrachteten Stichprobe von 1000 Werten liegen unterhalb von diesem Wert.
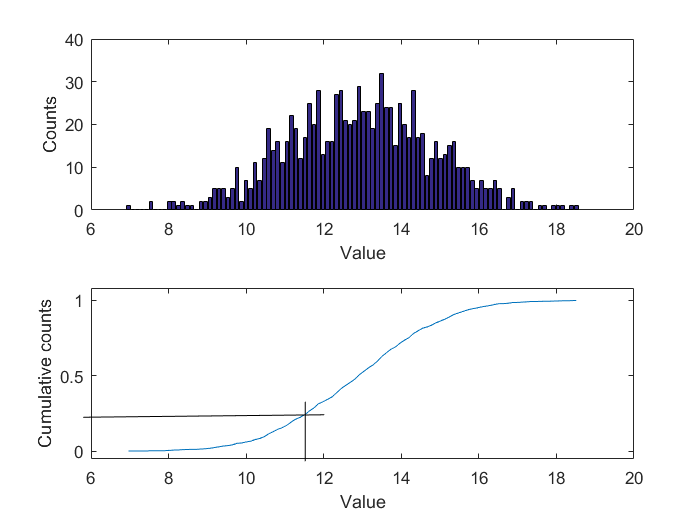
Der Bibliotheksbaustein zur Berechnung von Quantilen arbeitet in zwei Teilschritten, die gemeinsam oder in separaten Teilschritten aufgerufen werden können. Im ersten Schritt werden Werte einem internen Histogramm hinzugefügt, dessen Parameter vorab konfiguriert werden können. Dieser Schritt benötigt sehr wenig Rechenaufwand. Im zweiten Schritt werden aus dem gespeicherten Histogramm die zuvor ausgewählten Quantile berechnet. Diese zweite Operation ist je nach Konfiguration deutlich rechenintensiver, da sie durch aufwendigere Operationen definiert ist, muss aber viel seltener ausgeführt werden.
| Berechnung von Quantilen in TwinCAT 3 Zur Berechnung von Quantilen kann der Funktionsbaustein FB_CMA_Quantiles genutzt werden. Dabei können mehrere Quantile mit nur einem Bausteinaufruf berechnet werden. Parametrisiert wird der Baustein wie der Histogramm-Baustein sowie zusätzlich die zu berechnenden Quantile und der zu nutzende Stichprobenumfang. |