Optimization options
Sometimes the obvious way is not always the most efficient way. The following article shows some possibilities how you can optimize the S7 data communication.
Sample 1: reading many BOOL/BIT variables
The configuration in the TIA project contains several (in this sample 10) BOOL/BIT variables, which are located in the memory directly "one after the other" and are to be read out:
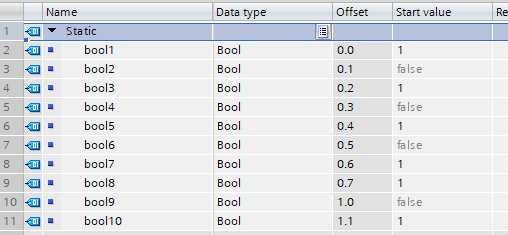
The most obvious implementation would be to attach the 10 variables of type BOOL to a request.
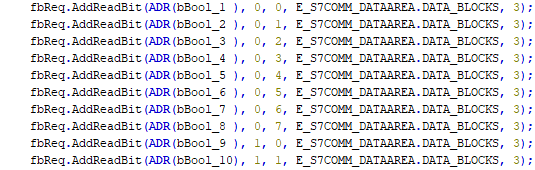
This implementation would then look like this:
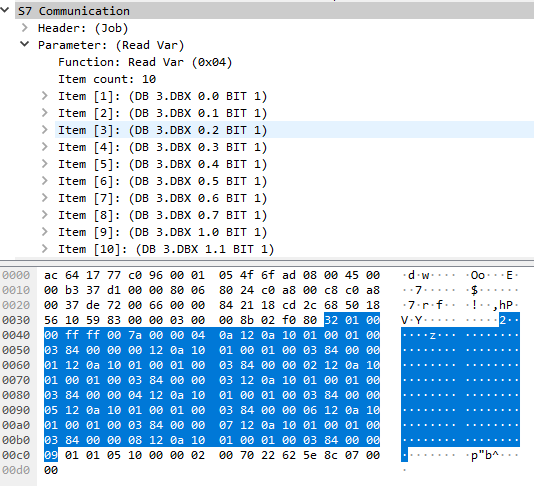
The various variables are queried individually here, with each "item" entry being 12 bytes long. The entire payload of the S7 request is thus 132 bytes long. A corresponding response would then look like the following:
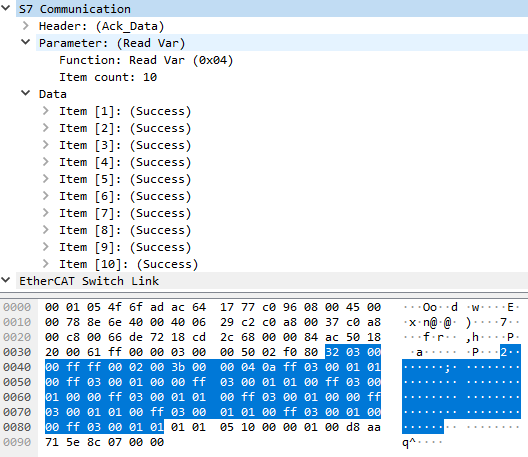
Each "Item" is 5 bytes long and the whole S7 Response 73 bytes.
A more efficient implementation would be to read a byte array, in this case 2 bytes.

The byte array would then be "mapped" to the BOOL variables.

The request in this case would look like this:
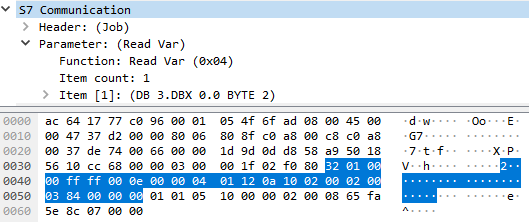
In this case, the payload is only 24 bytes long (i.e. 108 bytes less). The corresponding response would then be:
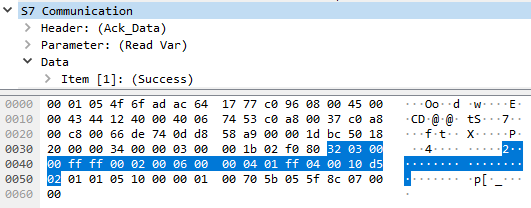
In this case, the payload of the response is only 20 bytes long (previously 73 bytes).
Request:
- Direct implementation: 132 bytes
- Optimized implementation: 24 bytes
- Savings: 108 bytes
Response:
- Direct implementation: 73 bytes
- Optimized implementation: 20 bytes
- Savings: 53 bytes
 | Further information If a request frame is longer than the S7 Controller can process, the TwinCAT 3 S7 communication driver must split the request into several requests. This can extremely increase the response time. |
Sample 2: reading out many WORD variables
The configuration in the TIA project contains several (in this sample 5) WORD variables, which are located in the memory directly "one after the other" and are to be read out:
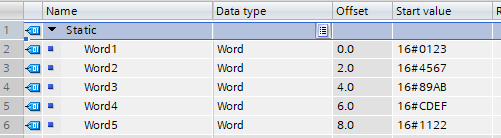
The same principle applies as in sample 1: each entry increases the payload size of the request and the associated response. The same approach can be used for optimization (please note the "endianess"). An optimized PLC program could then look as follows:
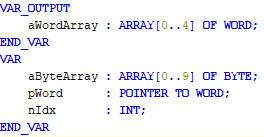
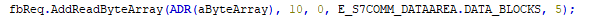
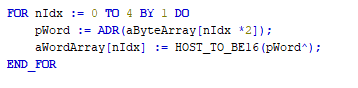
The entries must then be "mapped" accordingly and "rotated" correctly.
The savings compared to direct (obvious) implementation would then be as follows:
Request:
- Direct implementation: 72 bytes
- Optimized implementation: 24 bytes
- Savings: 48 bytes
Response:
- Direct implementation: 44 bytes
- Optimized implementation: 28 bytes
- Savings: 16 bytes