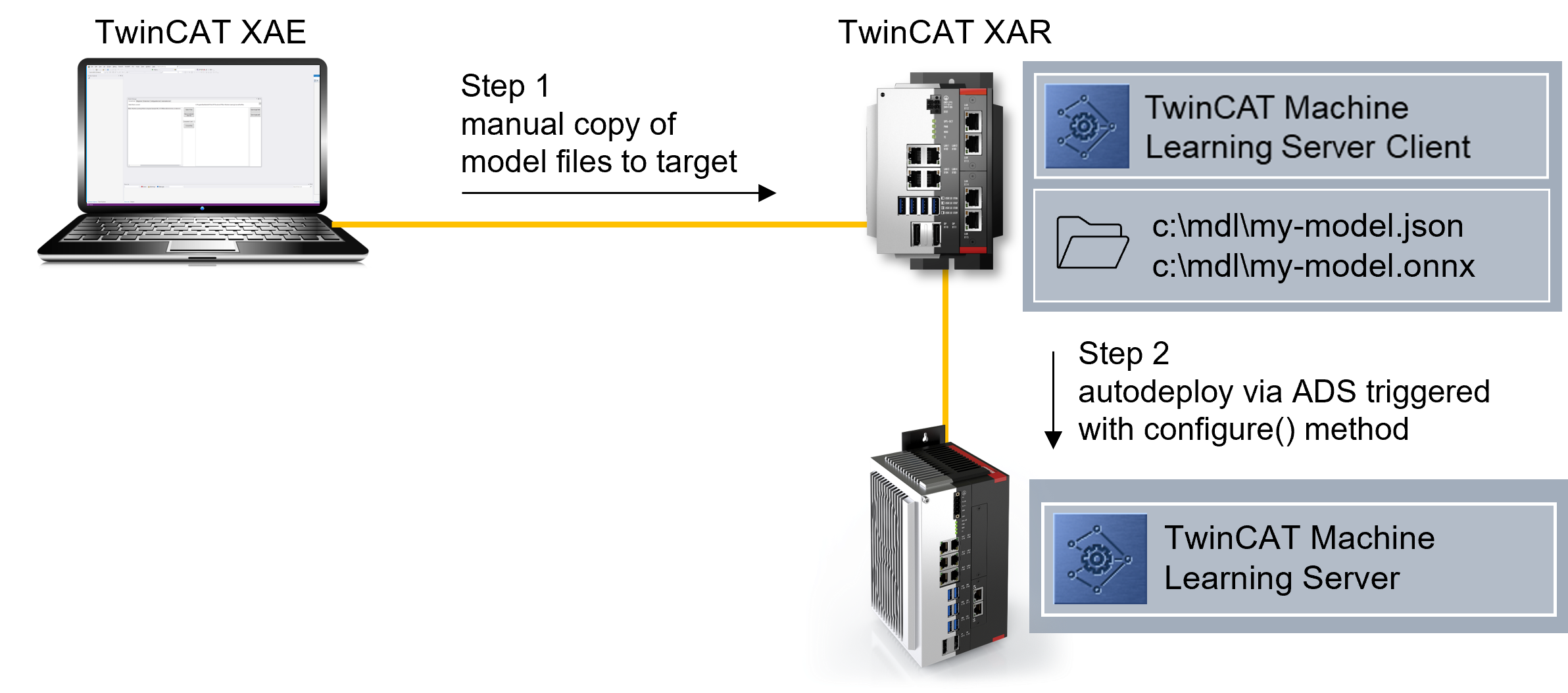
Make model description files available on the Server Device
In order to be able to load models, they must be made known to the TwinCAT Machine Learning Server. This means that the server must know the location of the created JSON and ONNX file on the file system in order to successfully load the AI model. This announcement is made using the Configure method. The method is passed the full path to the JSON file, which contains the interface description. The associated ONNX file must be stored in the same folder path. A hash is always used to validate the connection between JSON and ONNX.
The ONNX file is required on the device on which the TwinCAT Machine Learning Server is installed. The JSON file, in turn, is required on the client device. The storage path itself is arbitrary; but JSON and ONNX must have the same path.
Variant 1 - Client and server are installed on the same IPC: The JSON and ONNX file must be stored on the IPC in any path.

Variant 2 - Client and server are installed on different IPCs: The ONNX file can be stored directly on the server. The JSON file must then be stored on the client device under the same path.
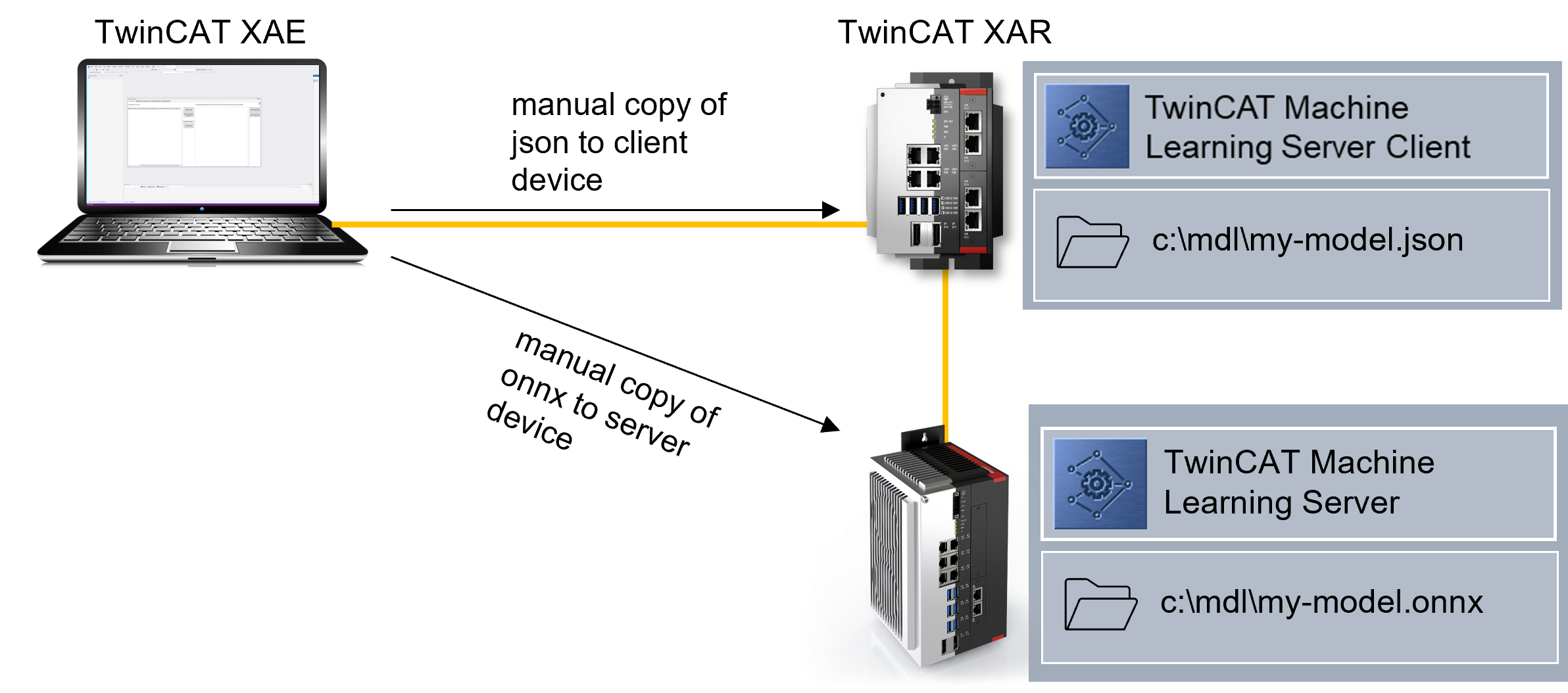
Variant 3 - Client and server are installed on different IPCs: The model files (ONNX and JSON) can alternatively both be stored on the client. When the Configure method is called, the path on the Server Device is checked first. If the ONNX file is not found there, the path on the Client Device is checked. If the JSON and ONNX are found on the Client Device, the ONNX file is transferred to the server device via ADS and then loaded from the server. This variant is time-consuming and is only carried out once for this model. The model is then loaded directly from the Server Device.
 | The ADS router memory must be large enough to be able to send the model via ADS. |