DenStream

DenStream is an implementation of the unmonitored, density-based clustering algorithm of the same name [1]. The latter is based on the well-known clustering algorithm DBSCAN [2, 3] and is particularly suitable for data streams whose structures change over time.
The number of input channels (referred to below as n) for this algorithm can be selected by the user. These inputs form the n-dimensional feature space in which clusters can be found. In each analysis cycle, the data stream provides the algorithm with a new feature vector that can be interpreted as a data point in this feature space. Clusters are separable areas with a high density of data points in the feature space.
In the first phase of the algorithm, the incoming data points are assigned to so-called micro-clusters (MCs). These micro clusters have properties (such as center point, weight and variance) that depend on the data points they contain. Only micro-clusters whose weight exceeds a certain threshold enter the second phase and are clustered by the DBSCAN algorithm. Thus, it is not necessary to retain the information about each data point. This reduces memory requirements, because over time there are far fewer micro-clusters than data points. Also, the computing effort for the DBSCAN algorithm is much lower since it runs over the reduced set of micro-clusters rather than all the data points. It is also possible to apply a fading function to the weights of the micro clusters. In this way, old data points lose their importance to the clustering process over time. This allows the algorithm to capture changes (such as the movement of clusters or their disappearance/appearance over time).
The DenStream algorithm has further advantages over other clustering algorithms. The user does not need to know the number of micro-clusters in advance, as the DenStream algorithm determines this number automatically. In addition, the algorithm is able to detect outliers in the data that does not belong to any cluster. Since it is a density-based algorithm, it is even possible to detect separate clusters of any shape (even if they are intertwined).
Parameter setting
Here we give a short introduction to how the algorithm works, mainly to give the reader a quick introduction to the parameter setting. For a deep understanding of the algorithm and its parameters, we refer the reader to the publications mentioned. Most of the terms and parameter names used here come directly from these publications.
The parameters of the DenStream algorithm mainly affect the following properties of the algorithm:
- the coarseness of the micro-clusters,
- the maximum distance between data points/micro-clusters so that they are assigned to the same cluster,
- the minimum density so that data points are identified as clusters and not as outliers,
- The fading rate at which older data points lose their significance.
The Parameters Epsilon, Lambda and Mu x Beta belong to the first phase of the algorithm, the formation of micro-clusters.
If possible, a data point is inserted into the micro-cluster whose center is closest to the data point. For this purpose, the Euclidean distances between the data point and the center points of all micro-clusters are compared and the micro-cluster with the smallest distance is selected. The data point can only be inserted into the micro-cluster if the radius of the micro-cluster does not exceed the Epsilon threshold after insertion. The radius is analogous to the variance of all data points contained in the micro-cluster. This means that data points can also be integrated into a micro-cluster even if their Euclidean distance to the center of the cluster is greater than Epsilon, as long as there are enough other points in the micro cluster with a smaller distance.
If the data point cannot be inserted into the nearest micro-cluster, a new micro-cluster is created with that data point. The weight of the respective micro-cluster is increased by one with the insertion of a data point.
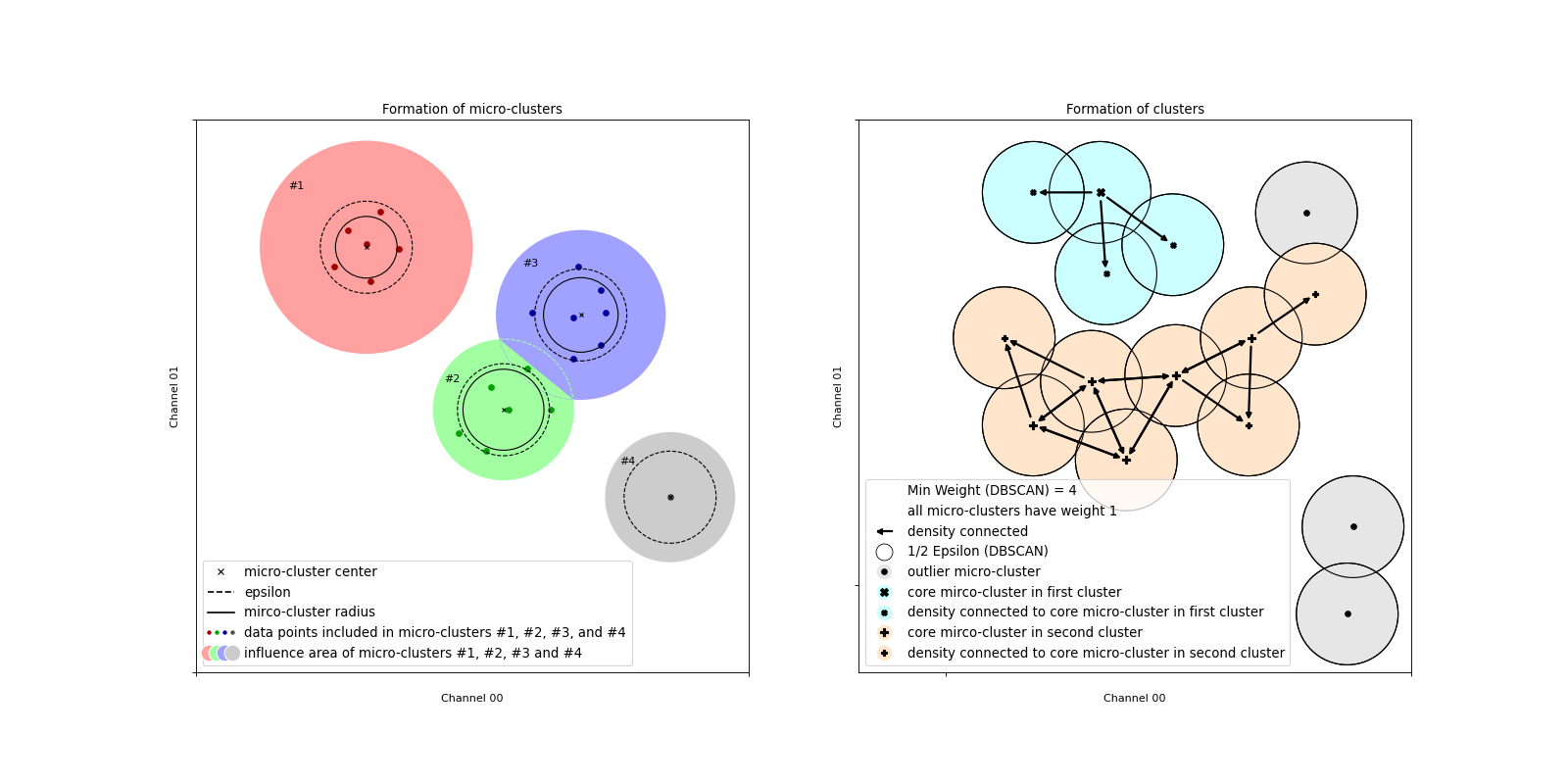
In the left-hand plot in the illustration, the assignment of the data points to the micro-clusters is sketched for two input channels as an example. 20 data points assigned to four different micro-clusters are shown. The first micro-cluster (#1, marked in red) contains six data points, the second (#2, marked in green) also contains six, the third (#3, marked in blue) contains seven and the fourth (#1, marked in gray) contains only one data point. The area around the center of the micro-cluster in which a new data point would have to be located in order to be accepted into the respective micro-cluster with the specified epsilon (marked by dashed line) is colored. This sphere of influence is greater if the micro-cluster already contains several data points and they have a lower variance (see, for example, micro-clusters #1 and #2). In addition, the spheres of influence of multiple micro-clusters can overlap and mutually influence one another through their existence, see micro-cluster #2 (green) and #3 (blue). The data points are always assigned to the closer micro-cluster, for which reason the spheres of influence are separated by a straight line. In the plot, a data point can be seen that is assigned to the micro-cluster #2, but if the latter did not exist, then it would be assigned to micro-cluster #3.
Like in the original study [1], micro-clusters are divided into potential and outlier micro-clusters depending on their weight. Only potential micro-clusters are subsequently clustered by the DBSCAN algorithm. The data points in the outlier micro-clusters are marked as outliers. However, outlier micro-clusters are also stored and updated with new data points, as they can still develop into potential micro-clusters. The weight of a micro-cluster must exceed the Beta x Mu threshold in order to be counted as a potential micro-cluster. In the left-hand sketch in the illustration, for example, the micro-cluster #4 (gray) contains only one data point, thus has a weight of less than or equal to one and would be counted as an outlier micro-cluster for Beta x Mu = 1.
When a fading function is applied, the weight of the micro-clusters decreases over time. This fading rate is determined by the parameter Lambda. If the value is set to zero, no fading function is applied, otherwise the weights decrease by a factor of 2^(-Lambda) every second. If the weight of an outlier micro-cluster falls below an internal threshold (depending on Mu x Beta and Lambda), it is deleted from the memory.
The parameters Epsilon (DBSCAN) and Min Weight (DBSCAN) affect the second phase. These parameters were adopted from the DBSCAN algorithm [3].
The DBSCAN algorithm runs over the set of potential micro-clusters and assigns them cluster designations. This can be either the index of the cluster to which they belong, or the designation outlier. The data point currently being processed is then assigned the name of the micro-cluster to which it belongs.
How does DBSCAN cluster the micro-clusters? The algorithm works according to the concept of density accessibility. Objects (in this case micro-clusters) belong to the same cluster if they are density-connected. This means that there must be a chain of micro-clusters with a maximum distance Epsilon (DBSCAN). All micro-clusters forming this chain must satisfy a second condition. The sum of the weights of all micro-clusters within the distance Epsilon (DBSCAN) around each individual micro-cluster in this chain must exceed the threshold Min Weight (DBSCAN). Micro-clusters that are not density-connected to at least one micro-cluster that meets this second condition are marked as outliers.
This is shown in the right-hand sketch in the illustration. For simplicity, it is assumed here that the weight of all micro-clusters is equal to 1. This corresponds to the case where there is exactly one data point in each micro-cluster and no fading function has been applied. The two clusters (marked with an x (turquoise) and a plus (orange)) with the two outlier micro-clusters result when the Min Weight (DBSCAN) parameter is set to four. The micro-clusters marked with a capital "x" or "+" are core micro-clusters. This means that at least three more micro-clusters (plus the micro cluster considered = 4) have a maximum distance of Epsilon (DBSCAN) to these micro-clusters. The micro-clusters marked with a small "x" or "+" are not core micro-clusters, but are located in the Epsilon (DBSCAN) neighborhood of a core micro-cluster and therefore belong to the same cluster. The micro-cluster in the upper right corner, marked with a small dot, is an outlier micro-cluster. Although it is located in the Epsilon (DBSCAN) neighborhood of a micro-cluster that is counted as belonging to a cluster, it is not a core micro-cluster.
Likewise, the two micro-clusters at the bottom right are outliers. Although they are in the immediate Epsilon (DBSCAN) neighborhood, there are only two of them. The Min Weight (DBSCAN) threshold of the weights is not exceeded.
The parameters outMCs Buffer Size and potMCs Buffer Size are specific to this implementation of the algorithm and are required because the memory for outliers and potential micro-clusters must be allocated before execution. Thus, outMCs Buffer Size and potMCs Buffer Size limit the possible number of outliers and potential micro-clusters during runtime. The user must find values for these parameters so that this limit is not exceeded.
The maximum number of outliers and potential micro-clusters during the execution of the algorithm depends on the distribution of the input data, but also on the setting of the other parameters. There are fewer micro-clusters at higher values of Epsilon as this results in coarser micro-clusters that can contain data points from a wider range. In general, the number of outlier micro-clusters increases at the beginning of the analysis, but decreases again when outlier micro-clusters transform into potential micro-clusters. If the patterns in the data stream do not change over time, the number of micro-clusters settles after an initial phase.
The more micro-clusters there are, the higher the computing requirements. For all outliers and potential micro-clusters we compare the distance to a data point and then all potential micro-clusters must be included in the calculation of the DBSCAN algorithm. A compromise must therefore be reached between the computing speed and the coarseness of the micro-clusters.
What happens if the values of outMCs Buffer Size and potMCs Buffer Size are set too low and at some point during the analysis more micro-clusters are required to capture the input data points? In this case, the algorithm continues to assign the data points to the existing micro-clusters and marks the data points accordingly, but the existing micro-clusters are no longer updated to prevent the buffer from overflowing. This means that the clustering of the data points continues, but with an overall stagnated feature space (older set of micro-clusters). Changes in the pattern of the data stream could then no longer be detected.
[1] F. Cao, M. Ester, W. Qian, A. Zhou. Density-Based Clustering over an Evolving Data Stream with Noise. In Proceedings of the 2006 SIAM International Conference on Data Mining, S. 326-337. SIAM.
[2] M. Ester, H.-P. Kriegel, J. Sander and X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proc. of KDD, 1996.
[3] J. Sander, M. Ester, H.-P. Kriegel, X. Xu. Density-Based Clustering in Spatial Databases: The Algorithm GDBSCAN and its Applications. Data Mining and Knowledge Discovery 2, 169-194 (1998)
Optionally, a Boolean signal can be selected for the Enable Execution input so that the algorithm is only active if the value of the selected signal is TRUE.
Input values
- Update Micro Cluster: If TRUE, micro-clusters are updated by the incoming data. If FALSE, the existing micro-clusters remain unchanged and are only used to determine the cluster index of the incoming data points.
- Input 01, ..., Input 0n: These inputs form the feature space for which clustering is performed.
Configuration options
- Num Channels: Here you can modify the number of input channels.
- Epsilon: Threshold for the maximum radius of micro-clusters.
- Mu x Beta: Threshold for the weight of a micro-cluster between outlier and potential micro-cluster.
- Lambda: Specifies the fading rate of the algorithm. The weight of each data point decreases by a factor of 2^(-Lambda) every second.
- Epsilon (DBSCAN): Specifies the epsilon parameter of the DBSCAN algorithm.
- Min Weight (DBSCAN): Threshold for the sum of weights in the epsilon neighborhood of a micro-cluster for the DBSCAN algorithm.
- potMCs Buffer Size: Maximum number of potential micro-clusters. The memory is allocated to potMCs Buffer Size micro-clusters.
- outMCs Buffer Size: Maximum number of outlier micro-clusters. The memory is allocated to outMCs Buffer Size micro-clusters.
Output values
- New Result: Is TRUE if the new cluster index differs from the cluster index of the last cycle.
- MC Buffer Overflow: TRUE if the micro-cluster update is stopped to prevent overflow of potMCs or outMCs Buffer Size.
- Last Event: This is the timestamp of the last cycle with a change of the cluster index
- Last Switch: This is the timestamp of the last cycle with an alternation between updating and not updating micro-clusters (either by setting the input Update Micro Cluster to TRUE or by internally preventing an overflow of potMCs/outMCs Buffer Size).
- Number of potMCs: Indicates the number of potential micro-clusters currently present.
- Number of outMCs: Indicates the number of outlier micro-clusters currently present.
- Cluster Index: Specifies the cluster index that the DBSCAN algorithm outputs for the data point of the current cycle.
- Number of Clusters: Specifies the total number of clusters detected by the DBSCAN algorithm.
Standard HMI Controls
For the DenStream algorithm, the following HMI controls are available for generating an Analytics Dashboard:
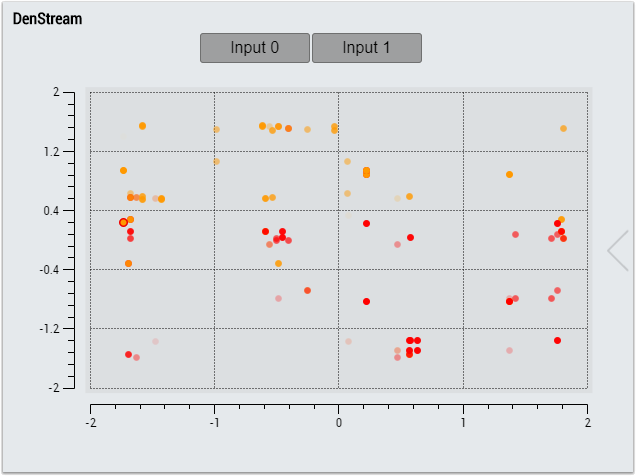
1. The DenStream control visualizes the inputs in the chart and their respective classification in a cluster (cluster index) in color. The buttons can be used to select the inputs to be displayed, up to two at a time. The slider on the right lists all output values: cluster count, number of potential micro-clusters, number of outlier micro-clusters, cluster index, last event, last switch.
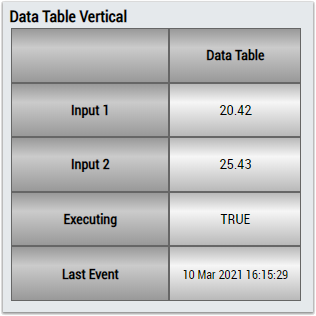
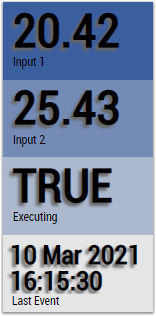
2. The Table Control or Multivalue Control visualizes all output values: cluster count, number of potential micro-clusters, number of outlier micro-clusters, cluster index, last event, last switch.

Alternatively, customer-specific HMI controls can be mapped in the DenStream algorithm using the Mapping Wizard.