Optimierungsmöglichkeiten
Manchmal ist der offensichtliche Weg nicht immer auch der effizienteste Weg. Der folgende Artikel zeigt einige Möglichkeiten auf, wie Sie die S7 Datenkommunikation optimieren können.
Beispiel 1: Auslesen von vielen BOOL-/BIT-Variablen
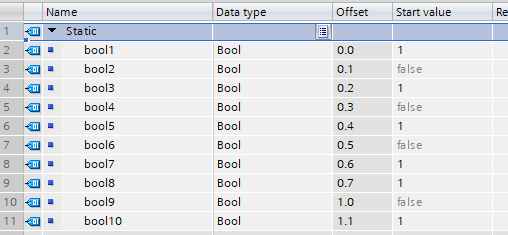
Die Konfiguration im TIA-Projekt enthält mehrere (in diesem Beispiel 10) BOOL-/BIT-Variablen, welche sich im Speicher direkt „nacheinander“ befinden und ausgelesen werden sollen:
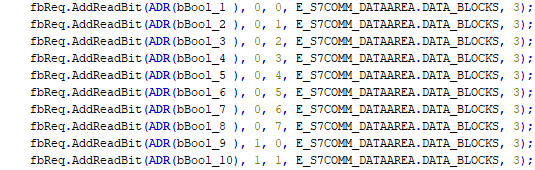
Die offensichtlichste Implementierung wäre es, die 10 Variablen vom Typ BOOL an einen Request zu hängen.
Auf dem Draht würde diese Implementierung dann wie folgt aussehen:

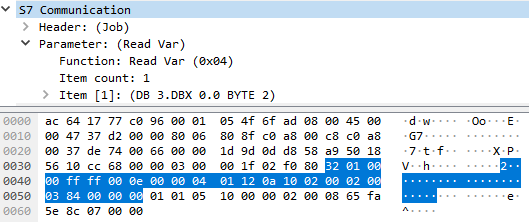
Die verschiedenen Variablen werden hierbei einzeln angefragt, wobei jeder „Item“-Eintrag 12 Bytes lang ist. Der gesamte Payload des S7 Request ist dadurch 132 Bytes lang. Eine entsprechende Response würde dann wie folgt aussehen:

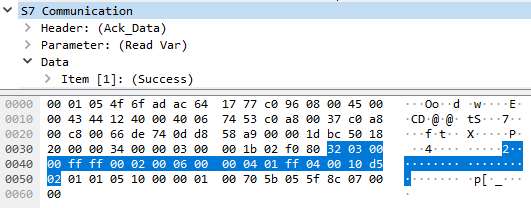
Jedes „Item“ ist hierbei 5 Bytes lang und der gesamte S7 Response 73 Bytes.
Eine (auf dem Draht) effizientere Implementierung wäre es ein Byte-Array zu lesen, in diesem Fall 2 Bytes.

Das Byte-Array würde dann auf die BOOL-Variablen „gemapped“.

Der Request würde in diesem Fall wie folgt aussehen:
Der Payload ist in diesem Fall nur noch 24 Bytes lang (also 108 Bytes weniger). Die entsprechende Response wäre dann:
Der Payload der Response ist in diesem Fall nur noch 20 Bytes lang (vorher 73 Bytes).
Request:
- Direkte Implementierung: 132 Bytes
- Optimierte Implementierung: 24 Bytes
- Ersparnis: 108 Bytes
Response:
- Direkte Implementierung: 73 Bytes
- Optimierte Implementierung: 20 Bytes
- Ersparnis: 53 Bytes
 | Weitere Informationen Wird ein Request-Frame länger als die S7-Steuerung verarbeiten kann, so muss der TwinCAT 3 S7 Kommunikationstreiber den Request in mehrere Requests aufteilen. Dadurch kann sich die Antwortzeit um ein Vielfaches erhöhen. |
Beispiel 2: Auslesen von vielen WORD-Variablen
Die Konfiguration im TIA Projekt enthält mehrere (in diesem Beispiel 5) WORD-Variablen, welche sich im Speicher direkt „nacheinander“ befinden und ausgelesen werden sollen:
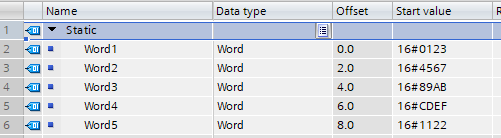
Hierbei gilt dasselbe Prinzip wie im Beispiel 1: jeder Eintrag erhöht die Payload-Größe des Requests und der zugehörigen Response. Zur Optimierung kann derselbe Ansatz gewählt werden (bitte beachten Sie die „Endianess“). Ein optimiertes SPS-Programm könnte dann wie folgt aussehen:
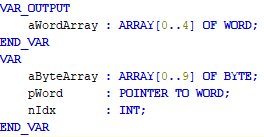
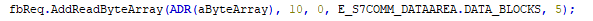
Die Einträge müssen dann entsprechend „gemapped“ und richtig „gedreht“ werden.
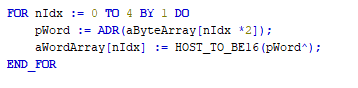
Die Ersparnis im Vergleich zur direkten (offensichtlichen) Implementierung wäre dann wie folgt:
Request:
- Direkte Implementierung: 72 Bytes
- Optimierte Implementierung: 24 Bytes
- Ersparnis: 48 Bytes
Response:
- Direkte Implementierung: 44 Bytes
- Optimierte Implementierung: 28 Bytes
- Ersparnis: 16 Bytes