SQL Query Editor
Der SQL Query Editor ist ein Tool des Database Servers, um die Entwicklung Ihrer Applikation zu unterstützen. Mit dem Tool können Verbindungen und SQL-Befehle getestet und die Kompatibilität zwischen SPS und Datenbanken geprüft werden.
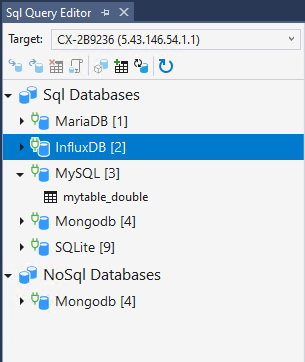
Nachdem der TwinCAT Database Server des Zielsystems gewählt wird, lädt der SQL Query Editor die aktuelle Datenbankkonfiguration und die Tabellen der erfolgreich verbundenen Datenbanken. Je nachdem, ob die Datenbank die SQL und die NoSQL-Schnittstelle (vom TwinCAT Database Server) unterstützt, wird sie unter der jeweiligen Kategorie aufgeführt.
Unter der Auswahl des Zielsystems befindet sich eine Statusleiste mit den verfügbaren Befehlen:
Tabellenebene |
|
Insert Arbeitsbereich | Öffnet den Insert-Arbeitsbereich, um Datensätze mit SQL in die ausgewählte Tabelle zu schreiben. |
Select Arbeitsbereich | Öffnet den Select-Arbeitsbereich, um Datensätze mit SQL aus der gewählten Tabelle zu lesen. |
Delete/Drop Arbeitsbereich | Öffnet den Delete/Drop-Arbeitsbereich, um Datensätze mit SQL aus der gewählten Tabelle zu löschen oder ganze Tabellen zu löschen. |
NoSQL Arbeitsbereich | Öffnet den NoSQL-Arbeitsbereich, um NoSQL-spezifische Abfragen auszuführen. |
Datenbankebene |
|
Stored Procedure Arbeitsbereich | Öffnet den Stored Procedure-Arbeitsbereich, um gespeicherte Prozeduren der Datenbank auszuführen. |
Tabellen Arbeitsbereich | Öffnet den Tabellen Arbeitsbereich, um neue Tabellen in der ausgewählten Datenbank zu erstellen. |
Tabellen aktualisieren | Aktualisiert die verfügbaren Tabellen der ausgewählten Datenbank. |
Allgemein |
|
Datenbanken aktualisieren | Aktualisiert den gesamten Datenbankbaum. |
Die Arbeitsbereiche werden rechts neben dem Baum unter dem entsprechenden Reiter geöffnet. Auch von der gleichen Tabelle können mehrere Reiter zu einem Zeitpunkt geöffnet werden.
Insert-Arbeitsbereich
Der Insert-Arbeitsbereich ermöglicht das Schreiben von Daten in die ausgewählte Tabelle über die TwinCAT Database Server Schnittstelle für SQL-Funktionsbausteine.
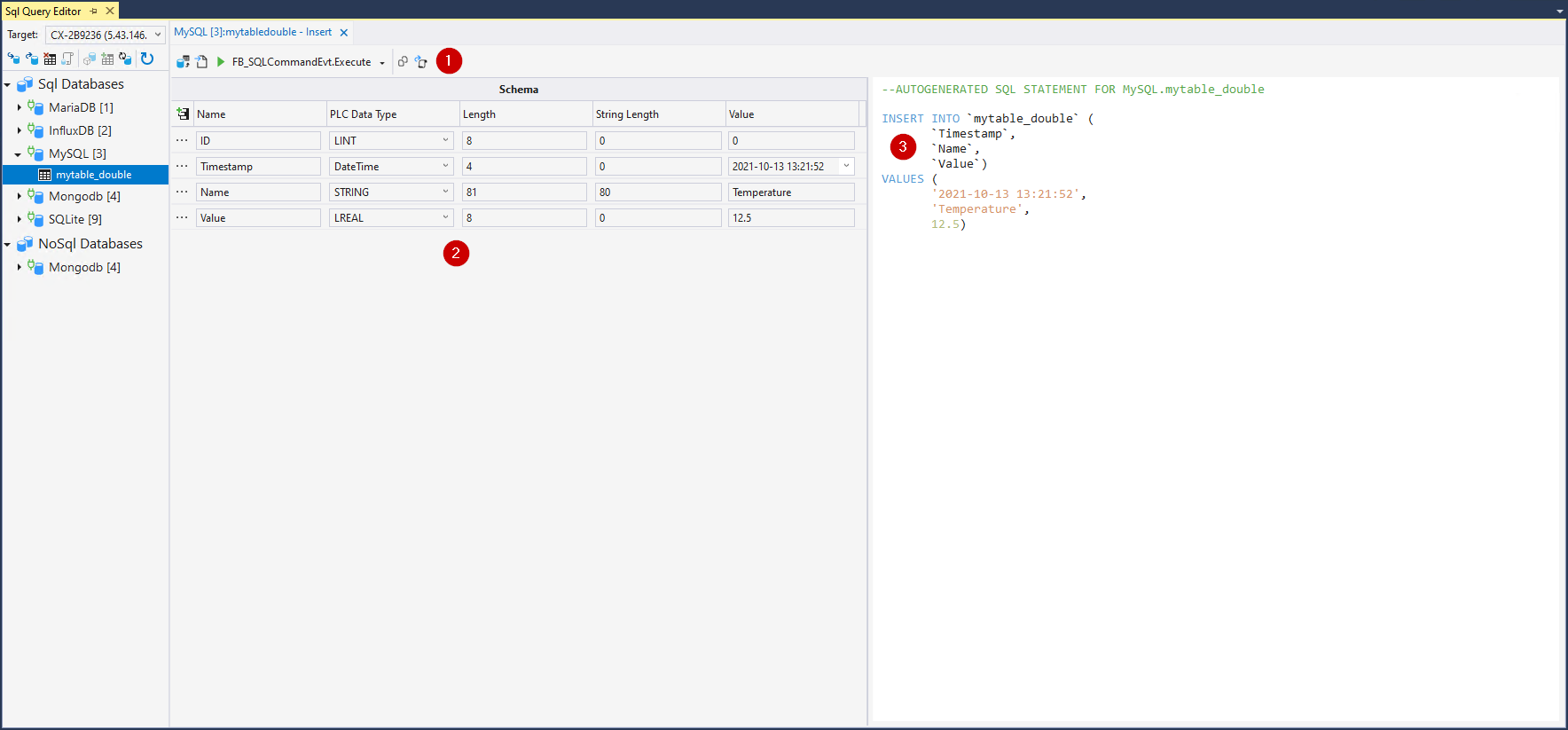
Im unteren Bereich (2) befindet sich eine Tabelle mit den einzelnen Datensymbolen im zu schreibenden Datensatz. Der Name, PLC-Datentyp, die Bytelänge sowie der Wert können hier bestimmt werden. Die eingetragenen Werte werden anschließend über den Befehl zum Generieren der SQL-Anweisung verwenden.
Diese SQL-Anweisung wird dann in einem Textfeld (3) zur Verfügung gestellt. Je nach Syntax der Datenbank kann der Inhalt unterschiedlich ausfallen.
In der oberen Statusleiste befinden sich die Kommandos zum Interagieren mit dem TwinCAT Database Server (1).
Kommando | Beschreibung |
|---|---|
Lese Tabellen Schema | Liest das Tabellenschema der Tabelle des Arbeitsbereichs aus. |
Generiere SQL-Anweisung | Generiert abhängig von der Datenbanksyntax aus der vorliegenden Tabelle die SQL-Anweisung. |
Ausführung | Führt über die jeweilige Schnittstelle des TwinCAT Database Server die im Textfeld (3) stehende Anweisung aus. |
Kopieren der Anweisung | Kopiert die im Textfeld (3) stehende Anweisung als TwinCAT kompatible Syntax. |
Exportieren als Struktur | Exportiert die Struktur der Tabelle der Eingabewerte zu einem TwinCAT 3 kompatiblen DUT. |
Select-Arbeitsbereich
Der Select-Arbeitsbereich ermöglicht das Lesen von Daten in die ausgewählte Tabelle über die TwinCAT Database Server Schnittstelle für SQL-Funktionsbausteine.
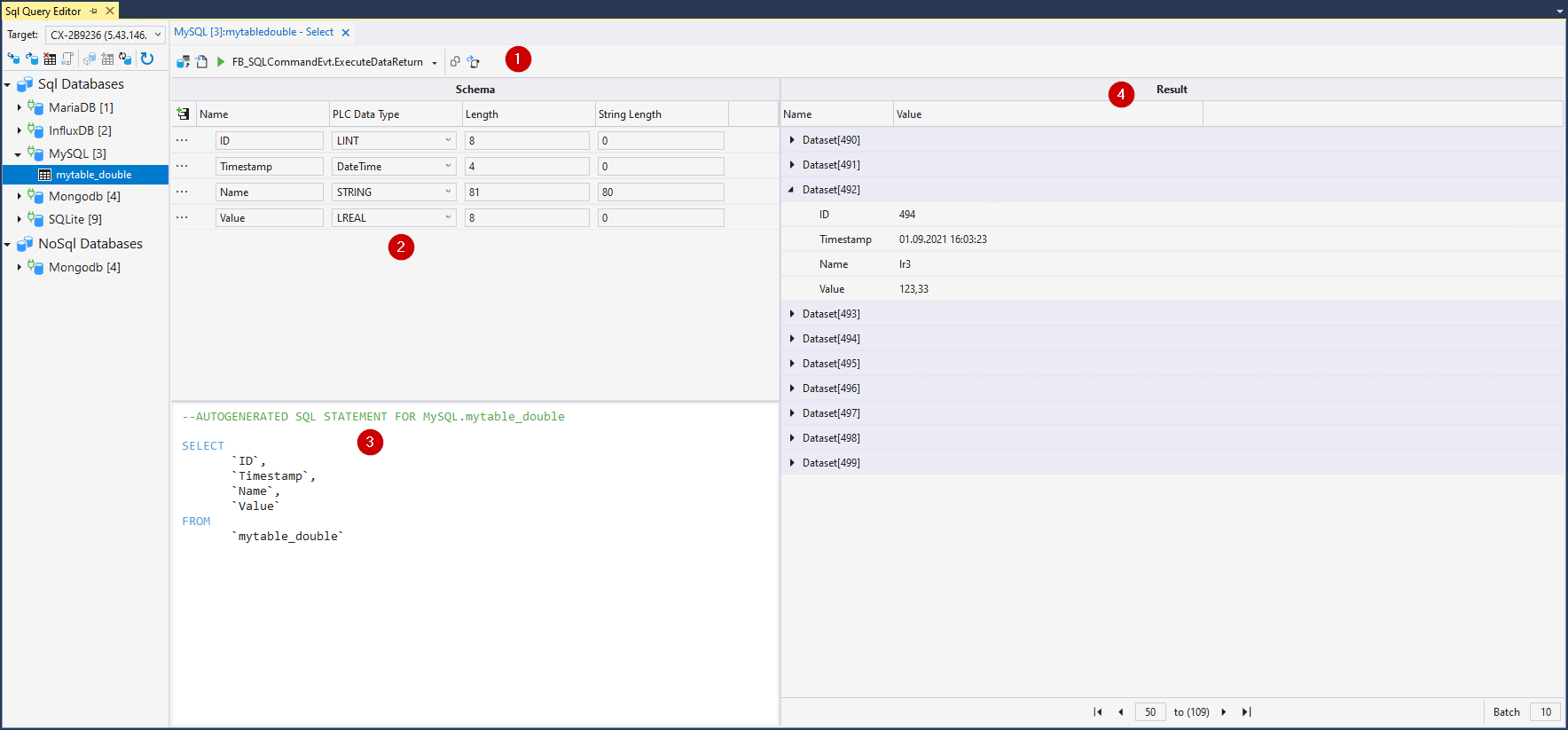
Im unteren Bereich (2) befindet sich eine Tabelle mit den einzelnen Datensymbolen im zu lesenden Datensatz. Der Name, PLC-Datentyp, sowie die Bytelänge können hier bestimmt werden. Diese Informationen werden anschließend zum Interpretieren der Daten benötigt.
Diese SQL-Anweisung wird dann in einem Textfeld (3) zur Verfügung gestellt. Je nach Syntax der Datenbank kann der Inhalt unterschiedlich ausfallen.
Im Ergebnis-Feld (4) werden nach Ausführung der Anweisung die Daten angezeigt. Falls mehrere Ergebnisse zurückgeliefert werden, können diese unter über die Seiten durchgeschaltet werden.
In der oberen Statusleiste befinden sich die Kommandos zum Interagieren mit dem TwinCAT Database Server (1).
Kommando | Beschreibung |
|---|---|
Lese Tabellen Schema | Liest das Tabellenschema der Tabelle des Arbeitsbereichs aus. |
Generiere SQL-Anweisung | Generiert abhängig von der Datenbanksyntax aus der vorliegenden Tabelle die SQL-Anweisung. |
Ausführung | Führt über die jeweilige Schnittstelle des TwinCAT Database Server die im Textfeld (3) stehende Anweisung aus. |
Kopieren der Anweisung | Kopiert die im Textfeld (3) stehende Anweisung als TwinCAT kompatible Syntax. |
Exportieren als Struktur | Exportiert die Struktur der Tabelle der Eingabewerte zu einem TwinCAT 3 kompatiblen DUT. |
Delete/Drop-Arbeitsbereich
Der Delete/Drop-Arbeitsbereich bietet die Option SQL-Anweisungen abzusetzen, um entweder Daten aus einer Tabelle oder die gesamte Tabelle aus der Datenbank zu löschen.
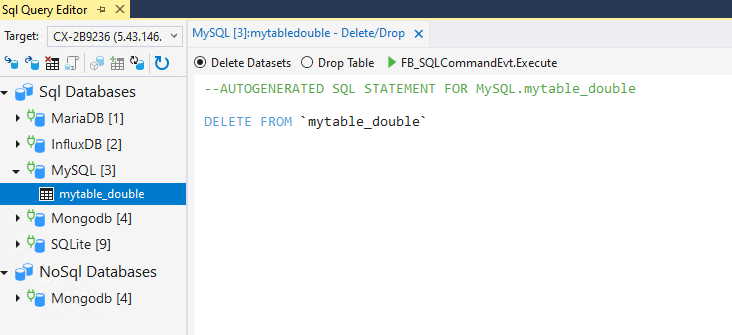
Hierfür kann zwischen den beiden Optionen in der Statusleiste ausgewählt werden. Die der Datenbank entsprechenden Syntax wird daraufhin im Anweisungsfeld generiert. Um diese mit der TwinCAT Database Server Schnittstelle auszuführen, steht der Schalter FB_SQLCommandEvt.Execute zur Verfügung.
NoSql-Arbeitsbereich
Der NoSql-Arbeitsbereich unterstützt die speziellen Funktionen von NoSql-Datenbanken bzw. der TwinCAT Database Server NoSQL-Schnittstelle.
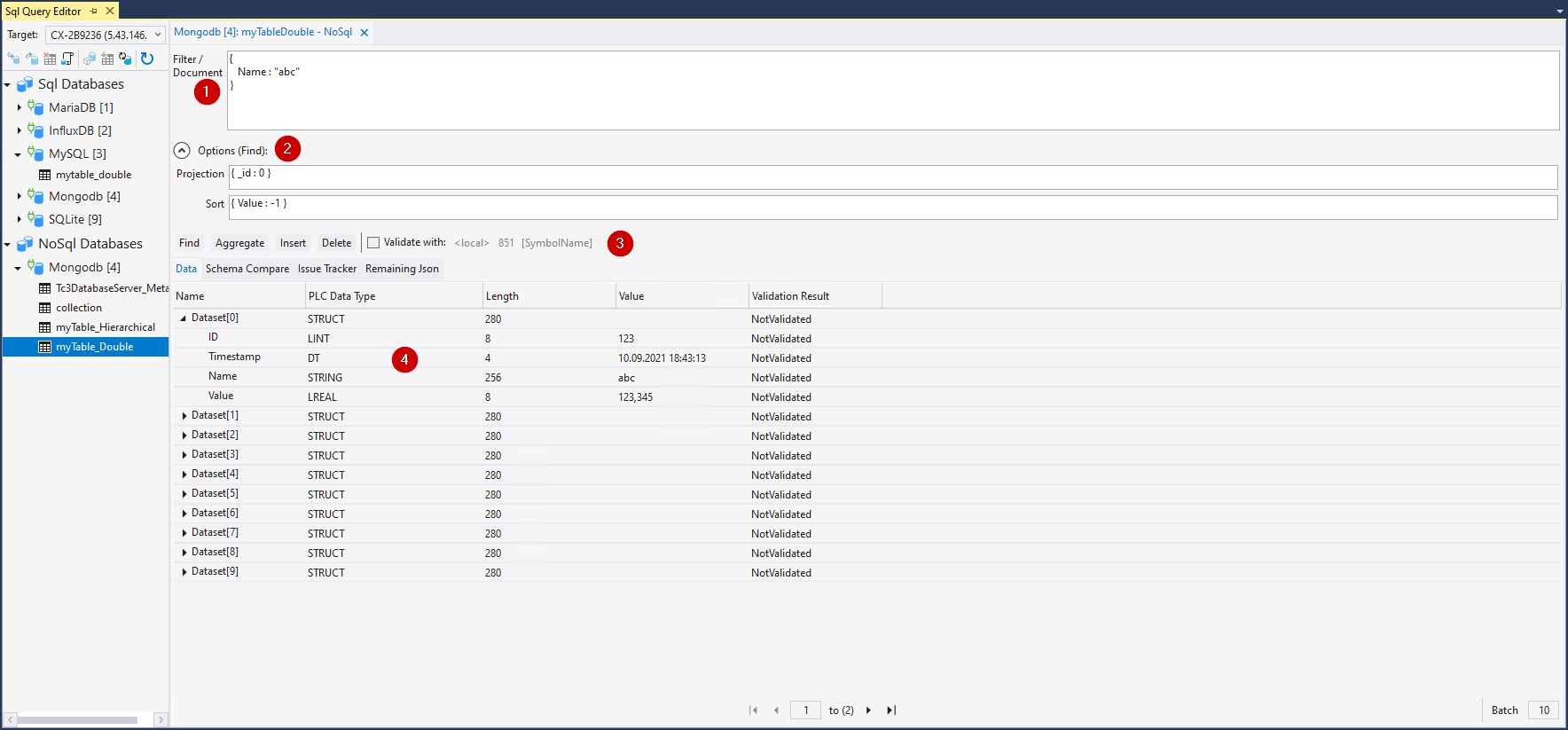
ID | Bezeichnung | Funktion |
|---|---|---|
1 | Filter/Document | Je nachdem welche Funktion genutzt wird, agiert dieses Eingabefeld als Dokument oder als Filter im Json-Format. Falls Sie einen Find ausführen möchten und zusätzlich eine Projektion oder eine Sortierung vornehmen möchten, lassen sich mit den darunterliegenden Options(Find) diese Felder füllen. |
2 | Options (Find) | Beschreibt zusätzliche Parameter für die Find-Funktion, wie die Projektion oder Sortierung. |
3 | Steuerelemente | Steuerelemente zur Interaktion mit der TwinCAT Database Server Schnittstelle für NoSQL. |
4 | Datenanzeige | Auflistung von zurückgelieferten Daten. Die Navigation ermöglicht die Iteration durch die verfügbaren Seiten. |
Find: Führt eine Suchabfrage mit dem im Textfeld (1) eingetragenen Filter aus. Optional kann ebenfalls über die Options(Find) -Felder eine Projektion oder eine Sortierung vorgenommen werden. Hierbei werden Daten zurückgeliefert und in der Datenanzeige (4) aufgeführt. Die Syntax der Filter ist dabei datenbankspezifisch.
Aggregate: Führt eine Aggregation mit dem im Textfeld (1) eingetragenen Parametern aus. Hierbei werden Daten zurückgeliefert und in der Datenanzeige (4) aufgeführt. Die Syntax der Filter ist dabei datenbankspezifisch.
Insert: Führt eine Insert-Abfrage des im Textfeld (1) eingetragenen (Json-)Dokuments oder Dokument-Array aus. Diese werden dann in die Collection geschrieben.
Delete: Führt eine Delete-Abfrage auf die Daten aus, welche mit dem Filter im Textfeld (1) gefunden wurden. Die gefundenen Daten werden aus der Collection gelöscht.
Validate: Wird diese Option angewählt werden die Datenabfragen nicht automatisch nach ihrem eigenen Schema geparst, sondern versucht diese Daten auf die Struktur des Symbols aus der SPS abzubilden, welches über diese Parameter angegeben wurde.
Bei letzterer Funktion kann eine Find-Abfrage zu Konflikten führen. Im Gegensatz zu Strukturen im SPS-Prozessabbild, müssen Datensätze in NoSql-Datenbanken keinem festen Schema folgen. Möglicherweise besitzen abgefragte Dokumente keine Daten zu einem bestimmten Element in der SPS-Struktur. Oder der Datensatz trägt Daten, welche nicht in der SPS-Struktur vorhanden sind. Zugeordnet werden diese Daten über den Namen bzw. dem Attribut „ElementName“ in der SPS.
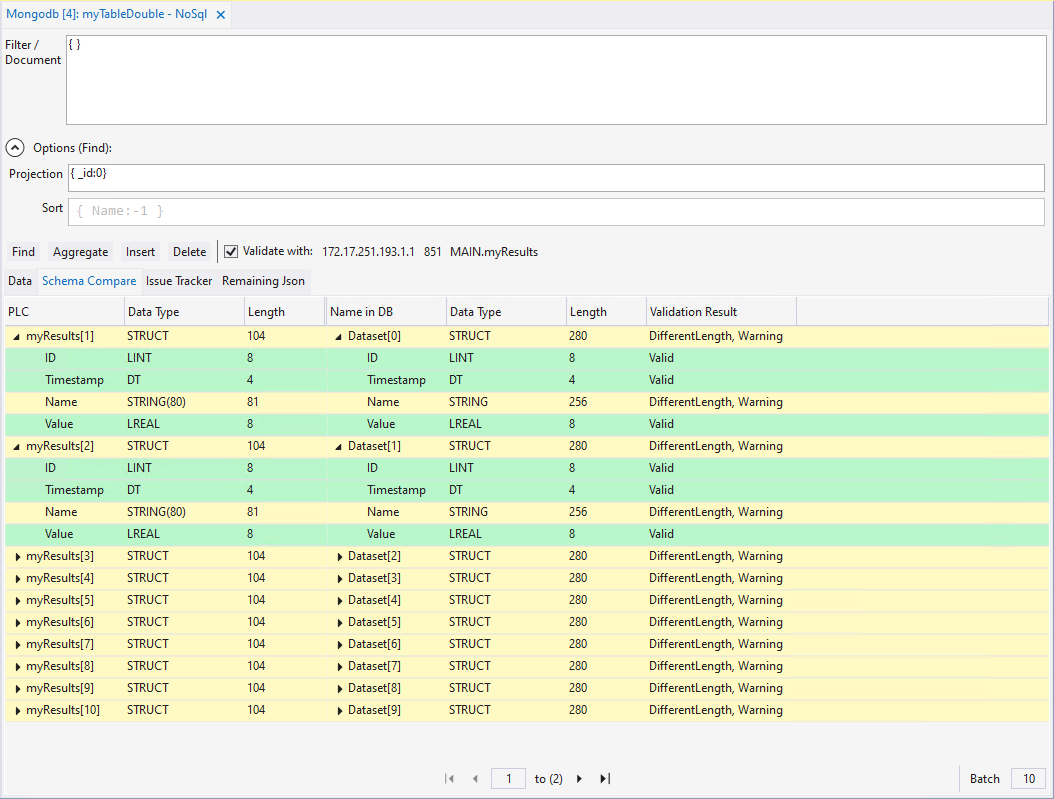
In der Registerkarte Schema Compare können die Unterschiede der Daten nachvollzogen werden. Im obigen Beispiel ist zu erkennen, dass im Falle des zurückgelieferten Dokuments in der PLC-Struktur die Variable „Name“ eine andere Datentyplänge hat als die der Datenbank. Die entsprechenden Farben zeigen die Gewichtung des Konflikts:
Rot: Es sind zu viele oder zu wenige Daten vorhanden.
Gelb: Die Bytelänge des Datensatzes stimmt nicht überein oder darunterliegende Datensätze sind übrig oder nicht vorhanden.
Grün: keine Konflikte
Diese Konflikte werden auch als Liste unter der Registerkarte Issue Tracker aufgeführt. Sie kann auch als String-Array bei Bedarf in die SPS eingelesen werden.
In der Registerkarte Remaining Json werden übrig gebliebene Datensätze als Json zurückgegeben. Auch diese Informationen können als String in die SPS gelesen werden.
Über die Steuerelemente in der Statusleiste kann, wie von den anderen Datendarstellungen bekannt, durch die Daten iteriert werden. Dabei kann die Menge der gleichzeitig angezeigten Datensätze angegeben werden.
Stored Procedure-Arbeitsbereich
Der TwinCAT Database Server unterstützt „Stored Procedures“, die viele Datenbanken bereitstellen, um komplexere Abfragen auf der Datenbankebene zu verarbeiten oder eine vereinfachte Schnittstelle zur Verfügung zu stellen.
Falls Stored Procedures in der Datenbank vorhanden sind, werden diese in der Dropdown-Liste der Statusleiste (4) aufgeführt.
Darunter befindet sich die Tabelle für die Eingangsparameter (1), sowie für das Ausgabe-Schema (2). Zusätzlich gibt es eine Ansicht für die Ausgabeergebnisse (3). Bei erfolgreicher Ausführung der Stored Procedure werden die Ergebnisse hier angezeigt.
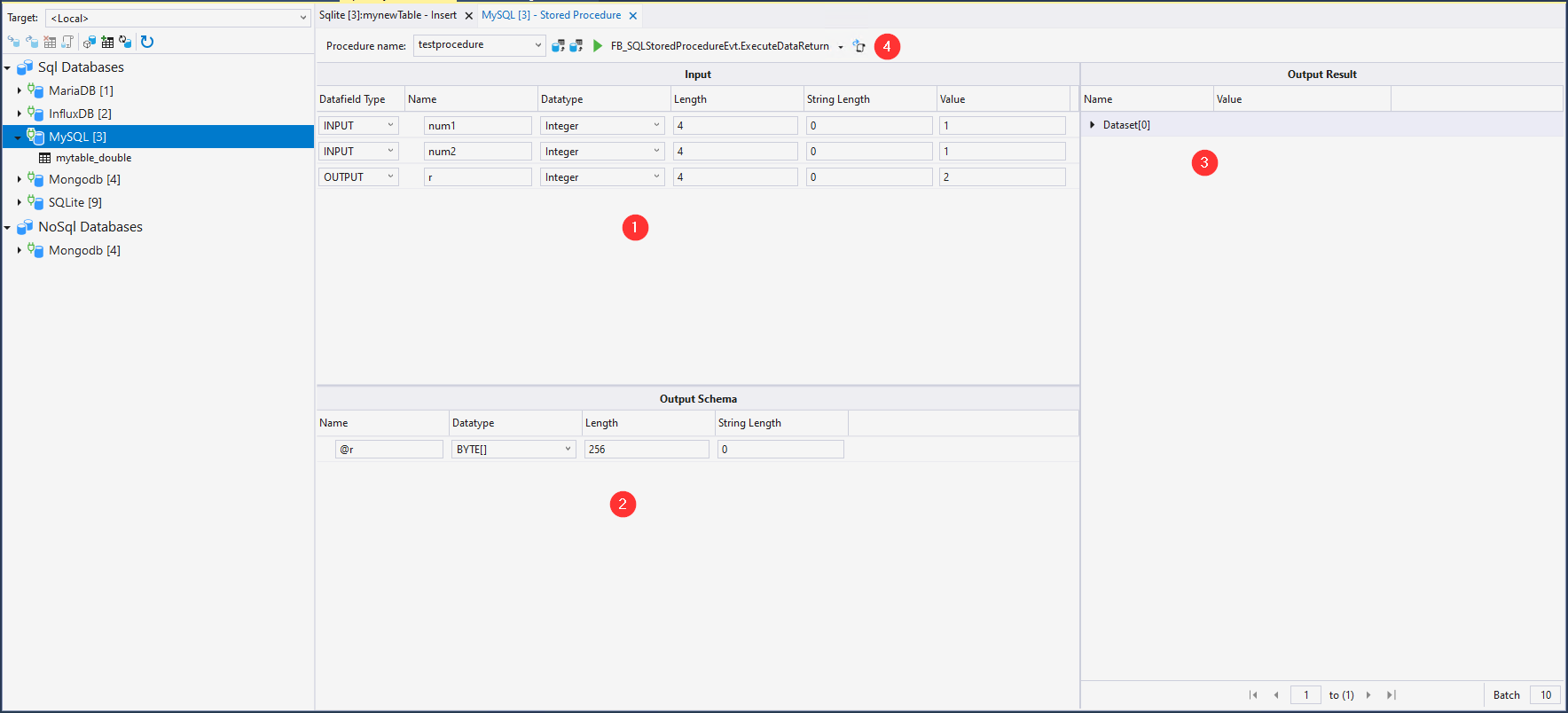
Die Statusleiste hat folgende Befehle:
Kommando | Beschreibung |
|---|---|
Lese Stored Procedure Eingangsschema | Liest das Eingangsparameterschema aus. Die Ergebnisse werden in der Tabelle 1 aufgeführt. |
Lese Stored Procedure Ausgangsschema | Liest das Ausgangsparameterschema aus. Die Ergebnisse werden in der Tabelle 2 aufgeführt. Info: Hierfür ist die Ausführung der Stored Procedure notwendig. Hierbei können je nach Programmierung Daten verändert werden. |
Ausführung | Führt über die jeweilige Schnittstelle des TwinCAT Database Server die Stored Procedure aus. |
Exportieren als Struktur | Exportiert die Struktur der Tabelle zu einem TwinCAT 3 kompatiblen DUT. |
Table-Arbeitsbereich
Der Table-Arbeitsbereich dient zur Erstellung von neuen Tabellen.
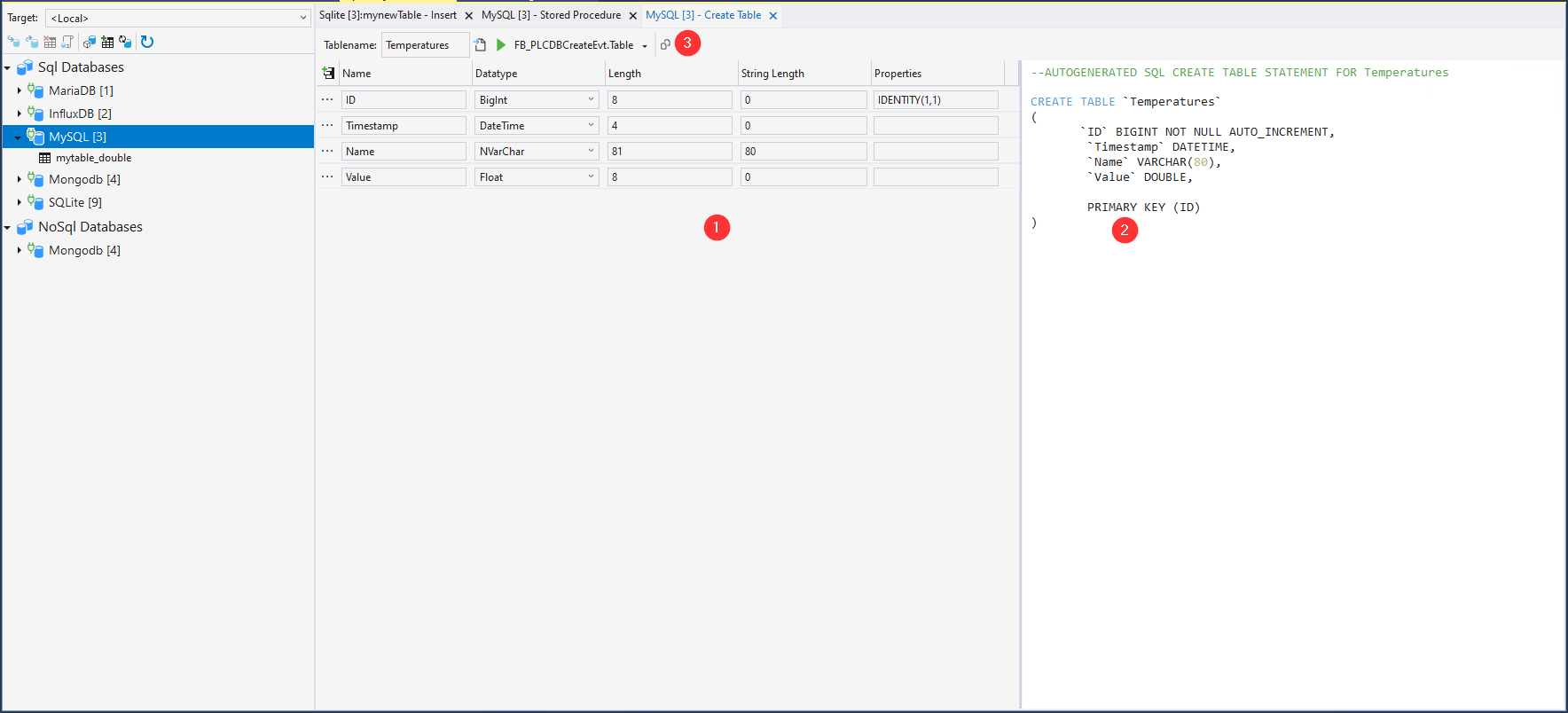
Hier kann die Tabellenstruktur (1) erstellt werden und daraus eine SQL-Anweisung im entsprechenden Feld (2) generiert werden. Hierfür kann die Statusleiste (3) mit folgenden Kommandos verwendet werden:
Kommando | Beschreibung |
|---|---|
Tabellenname | Bestimmt den Tabellennamen der neuen Tabelle. |
Generiere SQL-Anweisung | Generiert abhängig von der Datenbanksyntax aus der vorliegenden Tabelle die SQL-Anweisung. |
Ausführung | Führt über die jeweilige Schnittstelle des TwinCAT Database Server die Stored Procedure aus. |
Kopieren der Anweisung | Kopiert die im Textfeld (2) stehende Anweisung als TwinCAT kompatible Syntax. |