Mehrlagiges Perzeptron
Ein mehrlagiges Perzeptron (MLP) kann sowohl zur Klassifikation als auch zur Regression genutzt werden. Die Grundidee eines MLP ist die Verkettung kleinster Einheiten, sogenannter Neuronen, in einem Netzwerk. Jedes Neuron nimmt Informationen von vorherigen Neuronen oder direkt über Modelleingänge auf und verarbeitet diese. Dabei findet ein gerichteter Informationsfluss durch dieses Netzwerk von Eingaben zu Ausgaben statt.
Ein Neuron verarbeitet dessen Eingaben x als gewichtete Summe plus einen Ordinatenwert und transformiert das Zwischenergebnis mit einer Aktivierungsfunktion.
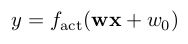
Neuronen werden üblicherweise in Schichten (Lagen) angeordnet, welche dann hintereinander verknüpft werden. Hat ein Netzwerk mehr als eine Lage zwischen Eingaben und Ausgaben, so spricht man von einem mehrlagigen Perzeptron.
Im untenstehenden Schaubild wird der Aufbau verdeutlicht.
- Input layer: Weist keine eigenen Neuronen auf. Dient als Eingabeschicht und definiert die Anzahl sowie den Datentyp der Eingaben.
- Hidden layer: Schicht mit eigenen Neuronen. Die Schicht wird charakterisiert durch die Anzahl der Neuronen sowie der gewählten Aktivierungsfunktion. Es können beliebig viele hidden Layer hintereinander geschichtet werden.
- Output layer: Schicht mit eigenen Neuronen. Die Anzahl der Neuronen sowie deren Aktivierungsfunktion richtet sich nach der zu realisierenden Applikation.

Unterstützte Eigenschaften
ONNX-Support
Unterstützt werden die ONNX-Operatoren:
- MatMul (matrix multiplication) gefolgt von ADD (add)
- GEMM (general matrix multiplication)
Darüber hinaus werden folgende Aktivierungsfunktionen unterstützt:
Aktivierungsfunktion | Beschreibung |
|---|---|
tanh | Tangens Hyperbolicus (-1,1) |
sigmoid | Sigmoid Funktion – eine Exponentialfunktion (0,1) |
softmax | Softmax – eine normalisierte Exponentialfunktion – oft für Klassifikation verwendet (0,1) |
sine | Sinus Funktion (-1,1) |
cosine | Cosinus Funktion (-1,1) |
relu | „Rectifier“ – Positiver Anteil ist linear – gute Lerneigenschaften bei tiefen Netzen (0,inf) |
abs | Absolutwert der Eingabe (0,inf) |
linear/id | Lineare Identität – einfache lineare Funktion f(x)=x (-inf,inf) |
exp | Eine einfache Exponentialfunktion e^(x) (0,inf) |
logsoftmax | Logarithmus von Softmax – manchmal effizienter als Softmax in der Berechnung (-inf,inf) |
sign | Vorzeichenfunktion (-1,1) |
softplus | Manchmal besser als relu, aufgrund der Differenzierbarkeit (0,inf) |
softsign | Bedingt besseres Konvergenzverhalten als tanh (-1,1) |
Beispiele für den ONNX-Support von MLPs aus Pytorch, Keras und Scikit-learn finden Sie hier: ONNX-Export eines MLP.
Unterstützte Datentypen
Es ist zu unterscheiden zwischen „supported datatype“ und „preferred datatype“. Der preferred datatype entspricht der Präzision der Ausführungs-Engine.
Der preferred datatype ist floating point 32 (E_MLLDT_FP32-REAL).
Bei Verwendung eines supported datatype wird eine effiziente Typ-Konvertierung automatisch in der Bibliothek durchgeführt. Durch die Typ-Konvertierung kann es zu minimalen Performance-Einbußen kommen.
Eine Liste der supported datatypes finden Sie unter ETcMllDataType.
Weitere Anmerkungen
Es sind seitens der Software keine Limitierungen bezüglich der Anzahl von Layern oder der Anzahl von Neuronen vorgesehen. Hinsichtlich Berechnungsdauer und Speicherbedarf sind die Grenzen der verwendeten Hardware zu beachten.