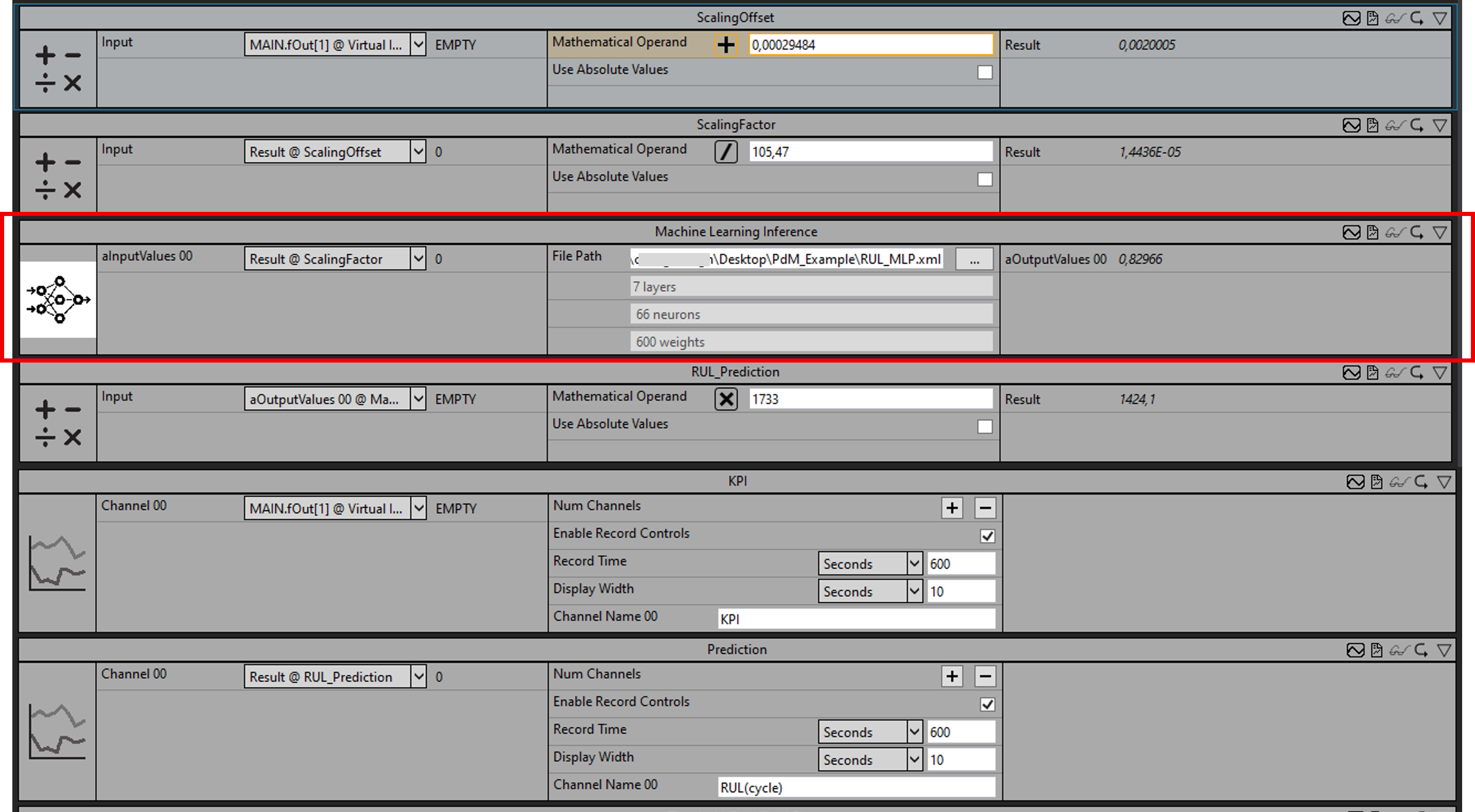
Übersicht
Einführung
Die Idee des maschinellen Lernens ist, auf Basis von Beispieldaten einen generalisierten Zusammenhang zwischen Eingaben und Ausgaben zu erlernen. Entsprechend wird hierzu eine gewisse Menge an Trainingsdaten benötigt, anhand derer ein Modell trainiert wird. Im Training des Modells werden Parameter des Modells über ein mathematisches Verfahren automatisch an die Trainingsdaten angepasst. Im maschinellen Lernen stehen dem Anwender eine Vielzahl von verschiedenen Modellen zur Verfügung. Die Wahl und die Auslegung der Modelle ist Teil des Engineering Prozesses. Unterschiedliche Modell-Typen oder Auslegungen von Modellen erfüllen unterschiedliche Aufgaben, wobei die wichtigste Unterteilung die Klassifikation und die Regression bildet.
Klassifikation: Das Modell erhält eine Eingabe (ein Bild, einen/mehrere Vektoren, …) und ordnet dieser eine Klasse zu. Der Ausgang ist entsprechend eine kategorische Größe. Diese Klassen können beispielsweise Gut-Teil oder Schlecht-Teil sein. Es könnten auch mehrere Klassen unterschieden werden, zum Beispiel Güteklasse A, B, C, D.
Regression: Das Modell erhält eine Eingabe und erzeugt eine kontinuierliche Ausgabe. Dabei werden nicht nur direkt gelernte Eingaben direkt gelernten Ausgaben zugeordnet (wie bei einem Look-up-Table), sondern das Modell ist zudem in der Lage, nicht gelernte Eingaben zu interpolieren, beziehungsweise zu extrapolieren, insofern es gut generalisiert. Es wird ein funktionaler Zusammenhang gelernt.
Ist ein Modell trainiert worden, kann es für die gelernte Aufgabe eingesetzt werden, d. h. das Modell wird zur Inferenz eingesetzt.
TwinCAT 3 Machine Learning Runtime
Beckhoff stellt mit den Produkten TF3800 TwinCAT 3 Machine Learning Inference Engine und TF3810 Neural Network Inference Engine Komponenten für die Inferenz von Modellen in der TwinCAT XAR zur Verfügung. Für beide Produkte wird eine gemeinsame Software-Basis genutzt, welche im Folgenden als Machine Learning Runtime (kurz: ML Runtime) bezeichnet wird.
Die ML Runtime ist ein in TwinCAT 3 integriertes Modul (TcCOM), welches in der TwinCAT XAR ausgeführt wird. Somit ist der Zugriff auf das Modell Interface (Modell-Inputs und Modell-Outputs) sowie auch die Ausführung des in der ML Runtime geladenen Modells in harter Echtzeit möglich.
Die Auftrennung zwischen TF3800 und TF3810 ist durch unterschiedliche Lizenzen begründet. Die benötigte Lizenz richtet sich nach dem zu ladenden ML-Modell. Grundsätzlich wird für das Laden und Ausführen von klassischen ML-Modellen die TF3800 vorausgesetzt. Für das Laden von Neuronalen Netzen wird die Lizenz TF3810 abgefragt. Die TF3810 beinhaltet die TF3800 Lizenz.
Weiterführende Informationen zu unterstützten Modellen und benötigten Lizenzen.
Workflow
Grundsätzlich besteht der Ablauf des maschinellen Lernens und die Integration in TwinCAT 3 aus drei Phasen:
- Dem Sammeln von Daten
- Dem Trainieren eines Modells
- Dem Deployment in die TwinCAT XAR
Zur Erhebung von Daten aus der Steuerung stehen Ihnen eine Vielzahl von TwinCAT-Produkten zur Verfügung:
Siehe TwinCAT Scope, TwinCAT Database Server, TwinCAT Analytics Logger, TwinCAT IoT, …
ML-Modelle können in einer Vielzahl von Software-Werkzeugen trainiert werden. Die Erstellung von ML-Modellen wird in der Regel in Programmierumgebungen wie Python oder R durchgeführt. Es existieren diverse Open Source und kostenfreie Werkzeuge, wie PyTorch, Keras und Scikit-learn, welche sich für das Erstellen von ML-Modellen eignen. Trainierte Modelle können aus diesen Werkzeugen in einem standardisierten Format, als ONNX Datei, exportiert werden. Die ONNX-Datei ist eine standardisierte Beschreibung des trainierten ML-Modells. Diese Datei wird zunächst in ein für TwinCAT aufbereitetes Format konvertiert (XML- oder BML-Datei).
Weitere Informationen:
Für das Deployment des Modells werden in TwinCAT zwei Wege angeboten:
- Es wird die Bibliothek TC3_MLL zur Nutzung in der SPS-Umgebung bereitgestellt. ML-Modelle können über einen Methodenaufruf asynchron geladen und anschließend, durch Aufruf einer weiteren Methode, zyklisch im SPS-Programm ausgeführt werden. Weiterführende Informationen zur PLC API
- Eine einfache Methode für maschinelles Lernen ohne Programmieraufwand: Ein TcCOM-Objekt, welches im TwinCAT-Objektbaum in der Entwicklungsumgebung eingefügt und konfiguriert werden kann. Das TcCOM lädt zum Systemstart das konfigurierte Modell und führt dieses in der zugeordneten Zykluszeit aus.
Weiterführende Informationen zum ML-TcCOM
Das folgende Schaubild illustriert die tiefe Integration der Machine Learning Runtime in die TwinCAT XAR. Das Modul ist, wie alle TwinCAT Runtime Objekte, ein TcCOM und es ist entsprechend tief verankert in der harten Echtzeit.
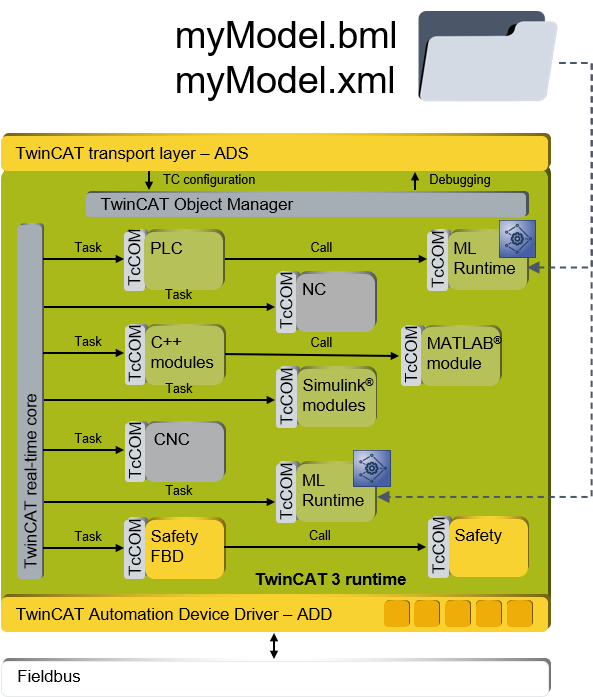
Integration von Machine Learning in TwinCAT Analytics
Die Produkte Machine Learning Inference Engine und Neural Network Inference Engine können auch in den TwinCAT Analytics Workflow integriert werden. Nähere Informationen dazu entnehmen Sie der TwinCAT Analytics Dokumentation.