Machine Learning Cheat Sheet: Auswahl von Modellen
Welches der unterstützten Modelle passt auf meine Problemstellung? Diese Frage wird häufig gestellt. Folgende Ausführungen sollen bei der Auswahl geeigneter Algorithmen behilflich sein.
Art der Eingangsdaten (Input-Daten) des Modells
Eine erste wesentliche Fragestellung betrifft die Art der Input-Daten des Modells: Bilddaten, Zeitreihen oder Tabular Data?
 | Die unterstützten Modelle eignen sich hauptsächlich für Tabular Data. Damit ist gemeint, dass der Input des Modells ein Array von Werten bildet. |
Bilddaten
Für die direkte Verarbeitung von Bilddaten werden in der Regel Convolutional Neural Networks (CNNs) genutzt. Diese werden voraussichtlich ab Q3/2023 unterstützt. Für einen eingeschränkten Anwendungsbereich können auch MLPs ausreichende Ergebnisse liefern. Dabei werden die Bildpixel als Vektor in das Model gegeben.
Zielführend ist es darüber hinaus, aus den Bilddaten zunächst Features zu extrahieren und diese Features als Input-Daten eines KI-Modells zu verwenden. Zur Bildaufnahme, Vorverarbeitung und Feature-Generierung steht mit TwinCAT Vision eine leistungsfähige Bibliothek zur Verfügung. Die Features können dann als Array zusammengefasst und das Problem als Tabular Data Problem aufgefasst werden.
Zeitreihen
Für die direkte Verarbeitung von Zeitreihen, d. h. Reihen von Datenpunkten, bei denen die zeitliche Abfolge der Samples wesentliche Informationen tragen, werden in der Regel rekurrente Neuronale Netze, wie das LSTM genutzt. Diese werden voraussichtlich ab Q3/2023 unterstützt. Für einen eingeschränkten Anwendungsbereich können auch MLPs ausreichende Ergebnisse liefern. Dabei werden N-Samples als Vektor in das Model gegeben.
Zielführend ist darüber hinaus, aus den Zeitreihen Signal-Feature zu extrahieren und diese Features als Input-Daten eines KI-Modells zu verwenden. Zur Feature-Generierung von Zeitreihen eignen sich SPS-Bibliotheken, wie die Condition Monitoring Bibliothek oder die Analytics Bibliothek. In der Praxis hat es sich als sehr effizient herausgestellt, z. B. statistische Größen, wie Mittelwert, Standardabweichung, Maximal- und Minimalwert usw. über einen definierten Zeitausschnitt zu bilden. Der Zeitausschnitt kann dabei die Länge eines Prozessschritts sein, beispielsweise vom Beginn bis zum Ende eines Schnitts oder vom Beginn bis zum Ende eines Biegeprozesses. Neben statistischen Größen haben sich, insbesondere bei rotierenden Prozessen, frequenzbasierte Feature, wie die Signalleistung in definierten Frequenzbändern, als nützlich erwiesen. Die generierten Features werden dann in einem Array zusammengefasst und als Input für das KI-Modell verwendet. Entsprechend kann das Problem als Tabular Data Problem interpretiert werden.
Tabular Data
Tabular Data kann direkt als Input für die meisten KI-Modelle verwendet werden. Situationen, bei denen direkt ein Array von Input-Daten bereitsteht, können sein: Es wird mit unterschiedlichen Messmitteln die Länge, Breite, Masse sowie dessen optische Komponenten in R-, G-, und B-Werten, gemessen. Die Werte können direkt als Array von 6 Elementen zusammengefasst und als Input für ein KI-Modell verwendet werden – zum Beispiel zur Klassifikation in OK oder nicht OK.
Beschreibung der Zielstellung
Ist die Art der Eingangsdaten definiert, stellt sich die Frage, was genau das KI-Modell leisten soll bzw. unter gegebenen Bedingungen leisten kann. Sind annotierte (gelabelte) Daten vorhanden und von welchem Typ sind die Label?
Clustering
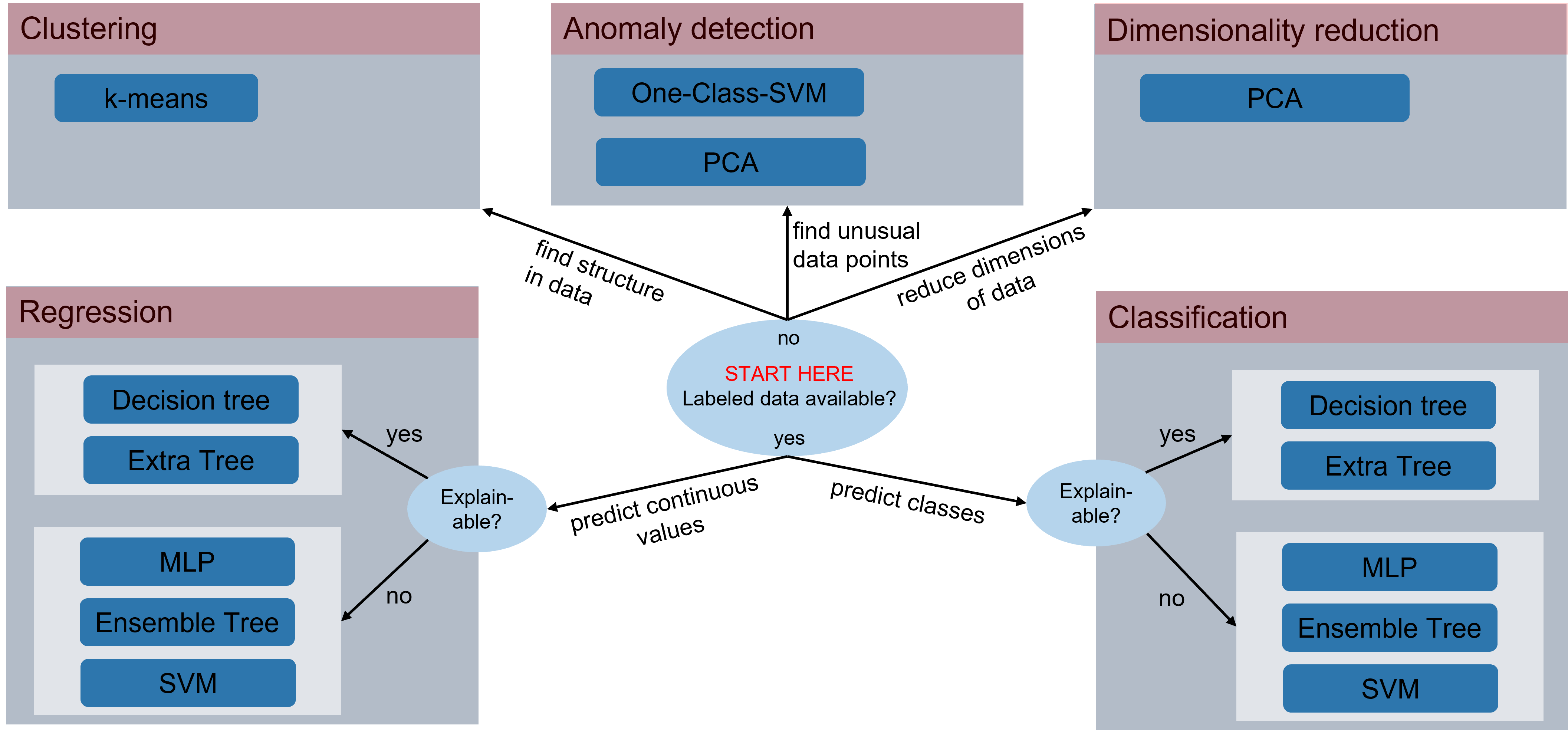
Beim Clustering wird die innere Struktur der Eingangsdaten analysiert. Bei der Cluster-Analyse sind keine annotierten Daten notwendig, allerdings muss die Anzahl k der erwarteten Cluster bekannt sein.
Anomaly detection
Eine beliebte Anwendung, ebenfalls für den Fall, dass keine annotierten Daten vorhanden sind. In der Trainingsphase werden dem Modell nur Daten präsentiert, welche als „Normal“ zu bezeichnen sind. In der Inferenzphase kann das Modell unterscheiden zwischen bekannter Eingangsdatenstruktur und unbekannter Eingangsdatenstruktur. In letzterem Fall wird von einer Anomalie ausgegangen. Herausforderung bei der Anomaliy detection ist das preprocessing der Trainingsdaten, sodass möglichst nur der Normal-Fall im Training genutzt wird sowie die limitierte Aussagekraft des Ergebnisses.
Dimensionality reduction
Menschen können sich bildlich den 2- und auch 3-dimensionalen Raum gut vorstellen. Punktewolken in einem 3D-Plot sind handhabbar und können das Verständnis über Prozesse verbessern. Sind mehrere Dimensionen beteiligt, wird es schnell unübersichtlich. Bei der Dimensionsreduktion geht es darum, einen N-dimensionalen Eingangsvektor auf einen kleineren Vektor abzubilden, wobei möglichst wenig Informationen verloren gehen sollen: Zum Beispiel wird ein 10-dimensionaler Eingang auf 3 Dimensionen reduziert und dabei bleiben 95% der Informationen erhalten. Ausgenutzt werden redundante Informationen der Eingangsdaten. Die Dimensionsreduktion eignet sich gut als Feature-Generierungsschritt, z. B. vor einem Klassifikator.
Regression
Ein Regressionsproblem setzt voraus, dass ein annotierter Datensatz vorliegt. In der Regel wird ein Problem beschrieben mit N REAL oder LREAL als Eingang des Modells und M REAL oder LREAL als Ausgang.
Beispiel: Bei einem Verformungsprozess werden N Features erstellt (z. B.: Maximum, Standardabweichung, Schiefe des Servomotorstroms). Zu diesen Features ist jeweils bekannt der resultierende Durchmesser des verformten Produkts in Längs- und Querrichtung. Aus den 3 Features werden entsprechend 2 Werte geschätzt.
Soll der Verlauf einer Zeitreihe modelliert werden, kann man als Eingangsvektor die N vergangenen Zeit-Werte nutzen und den N+1 Wert als Label verwenden. Somit entfällt das händische Labeln der Daten.
Classification
Ein Klassifikationsproblem setzt einen annotierten Datensatz voraus. Hier werden in der Regel N REAL- oder LREAL-Werte auf eine Kategorie, in TwinCAT in der Regel als INT dargestellt, abgebildet. Beispielsweise wird aus N Features berechnet, ob ein gefertigtes Produkt der Qualitätsklasse A, B oder C entspricht.
Erklärbarkeit eines KI-Modells
In manchen Situationen ist es von größter Bedeutung, die Ergebnisse eines KI-Modells erklären zu können, also bspw. die Frage zu beantworten, warum ein Modell ein Produkt als fehlerhaft eingestuft hat. Leider arbeiten die meisten Algorithmen wie Black Boxes, und die Ergebnisse sind nur schwer bis gar nicht zu erklären – auch wenn sie sehr genau sind. Entscheidungsbäume sind gut erklärbare Modelle, da man den Pfad durch den Baum mit den einzelnen Grenzwerten der Abzweigungen nachvollziehen kann. Allerdings ist die Accuracy dieser Modelle oft nicht so überzeugend wie bei anderen nicht erklärbaren Modellen.
KI-Modell Cheat Sheet
Folgende Abbildung gibt einen einfachen Leitfaden zur Wahl eines geeigneten KI-Modells. Sie veranschaulicht die Einordnung von KI-Modellen für unterschiedliche Anwendungszwecke; Vorausgesetzt, es handelt sich um Tabular Data als Modell-Input.