Task Einstellung
Applikationen mit mehreren Echtzeit-Tasks
Eine Condition Monitoring Analysekette wird gebildet aus der Datensammlung, meist mehreren Algorithmen und der Ergebnisbereitstellung. Die Weiterverarbeitung der Ergebnisse sowie programmatische Reaktionen auf diese sind applikationsabhängig.
Da der Umfang der Eingangsdaten, z.B. die Länge von Eingangsvektoren, stark von der jeweiligen Anwendung abhängt, benötigt Software zur Signalverarbeitung Arrays mit unterschiedlicher Länge und verschiedenen Elementtypen. Die TwinCAT 3 Condition Monitoring Library verwendet daher durchgängig eine flexible Datenstruktur für numerische Arrays. Diese erlaubt es, numerische Daten effizient blockweise zu speichern, zu übertragen und auszuwerten. Sie kann neben ein- auch mehrdimensionale Daten darstellen.
Die Condition Monitoring Algorithmen sind je nach Konfiguration sehr rechenaufwändig. Die Algorithmen werden deshalb bevorzugt in eine separate Task ausgelagert. Die Analysekette erstreckt sich in dem Fall über mehrere Tasks. Die damit verbundenen Schwierigkeiten des synchronen Datenaustausches und der Threadsicherheit werden von den Bibliotheksbausteinen intern gekapselt, so dass flexibel handzuhabende Analyseketten ermöglicht werden.
Mehr Informationen zum Datenaustausch finden sich im Kapitel „Parallelverarbeitung“.
Tipp: Selbstverständlich kann das Programm auch als Anwendung einer einzelnen Task implementiert werden. Dies wird empfohlen, wenn die benötigten Algorithmen, in Abhängigkeit der CPU und der Taskzykluszeit, schnell genug abgearbeitet werden können.
Taskzykluszeiten
Die Analyseschritte und die entsprechenden Puffergrößen stellen eine Bedingung für die Taskzykluszeit dar. Die Berechnung muss häufig genug ausgeführt werden, um alle Eingangsdaten verarbeiten zu können.
Beispiel: Die Datensammlung füllt Puffer, deren Größe bei der Deklaration auf 1600 Elemente festgelegt wurde. Mit einer Oversampling-Rate von 10 werden 160 Zyklen für die Füllung eines Puffers benötigt. Wenn die Signalsammlung von einer 1 ms Task ausgelöst wird, muss die Berechnung von einer Task mit einer Zykluszeit unter 160 ms ausgelöst werden.
Es wird empfohlen die Berechnungszykluszeit kleiner einzustellen, um eine schnellere Reaktion zu realisieren (mindestens Faktor 0,5). Auf der anderen Seite hängt die kleinstmögliche Berechnungszykluszeit von der Komplexität der zu berechnenden Algorithmen und von der Leistungsfähigkeit der genutzten CPU ab.
 | Richtwert für obere Schranke der Berechnungszykluszeit Berechnungszyklenzeit < 0,5 * Signalsammlungszyklenzeit * Puffergröße / Oversampling-Rate |
Die meisten Algorithmenbausteine (Spectrum, Cepstrum, …) umfassen rechenintensive mathematische Operationen. Sie sollten in einem Taskkontext mit ausreichender Zykluszeit aufgerufen werden. Die erforderliche Ausführungszeit hängt zudem von der Hardwareplattform ab. Die obige Gleichung stellt einen oberen Richtwert für die Berechnungszyklenzeit dar. Für die Abschätzung eines unteren Richtwerts wird bspw. für jeden Funktionsbaustein ein Profiler zur Verfügung gestellt, der im Verlauf der Online-Überwachung aktiviert werden kann. Sie finden diesen Profiler in der Instanz des Funktionsbausteins unter fbImplementation → fbExecutionTimeMonitoring. Durch manuelles Setzen von bMeasureMaxExecTime aktivieren Sie den Profiler. Es soll auf interne Variablen eines Funktionsbausteins wie gewohnt programmatisch nicht zugegriffen werden.
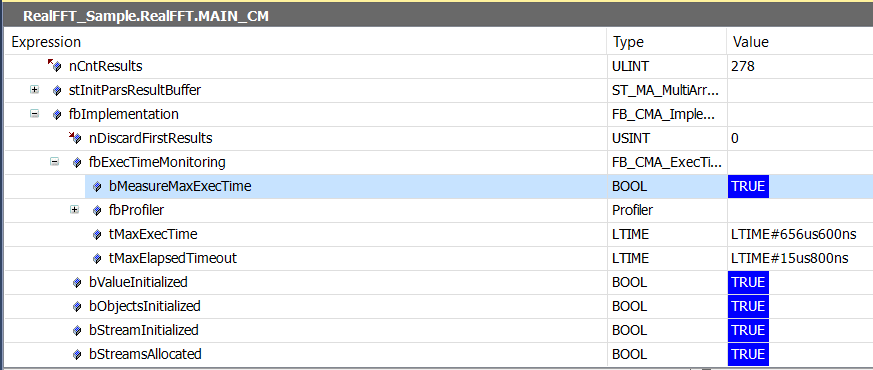
Die angezeigten Werte sind maximale Ausführungszeiten. Die Taskeinstellungen sollten eine kleine Reserve für mögliche Kombinationen von Parametern und Eingangswerten, die zu längeren Ausführungszeiten führen könnten, vorsehen.
Ausnahmen zu den obigen Betrachtungen bilden manche Statistik-Bausteine (Quantile, Histogramme, …). Diese Bausteine fügen in der Regel zunächst lediglich Daten für mehrere Taskzyklen dem internen Speicher hinzu. Nur die anschließende Berechnung (nach N Zyklen Daten sammeln) benötigt Zeit. Die entsprechende Taskzykluszeit kann dem einfachen Aufruf ohne Berechnung angepasst werden. Dies führt zwar zur Überschreitung der Zykluszeit im Falle eines Aufrufs mit Berechnung, sorgt aber für schnelle Reaktionszeiten. Dies ist ein Sonderfall für die SPS-Programmierung. Normalerweise sollte eine Taskzykluszeit niemals überschritten werden.
| Zykluszeit beachten Die Zykluszeit von Tasks, die ausschließlich Condition Monitoring Algorithmen aufrufen, können auf solch eine Weise angepasst werden, dass die Zykluszeit selten überschritten wird. Programmbausteine, die von dieser Task aufgerufen werden, sollten keinen anderen Programmcode enthalten! Und selbstverständlich muss die Priorität dieser langsamen Tasks niedriger sein, als die von anderen Tasks. |
Floating Point Exceptions
Diese Exceptions können getrennt für jede Task deaktiviert werden. Sie sind standardmäßig aktiviert.
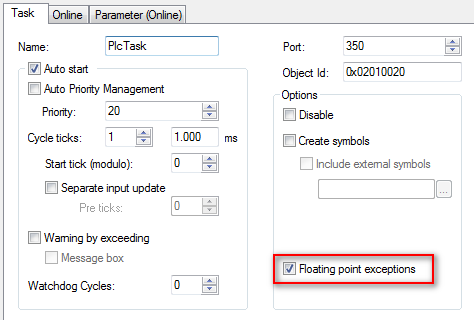
Einige Algorithmenaufrufe können ein NaN (Not a Number) als Ergebnis ausgeben. Wenn NaNs in der Anwendung abgearbeitet werden sollen, müssen die FP Exceptions für diese Task deaktiviert werden. Anschließend müssen Sie sich vergewissern, dass der gesamte Programmcode und alle verwendeten Funktionen NaNs verarbeiten können.
Weitere Hinweise bezüglich des Umgangs mit NaN Werten finden Sie im getrennten Kapitel „NaN Werte“.
| |
Ausführungsstopp Floating Point Exceptions sind standardmäßig aktiv. Vergleiche mit NaN (Not a Number) können eine solche Exception verursachen, die zu einem Ausführungsstopp führt, und möglicherweise einen Maschinenschaden verursachen. Es wird strengstens empfohlen, das Ergebnis für NaN zu überprüfen, bevor es verarbeitet wird. (siehe Kapitel „NaN Werte“) |
